# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# statisticsimport statsmodels.api as sm# pandas optionspd.set_option('mode.copy_on_write', True) # pandas 2.0pd.options.display.float_format ='{:.2f}'.format# pd.reset_option('display.float_format')pd.options.display.max_rows =7# max number of rows to display# NumPy optionsnp.set_printoptions(precision =2, suppress=True) # suppress scientific notation# For high resolution displayimport matplotlib_inlinematplotlib_inline.backend_inline.set_matplotlib_formats("retina")
이번 장에서는 시각화를 하기 전후로, 중요한 데이터 패턴을 보기 위해서 새로운 변수를 만들거나 요약한 통계치를 만들 필요가 있는데 이를 다루는 핵심적인 함수들에 대해 익힙니다.
대략 다음과 같은 transform들을 조합하여 분석에 필요한 상태로 바꿉니다.
변수들의 선택: subsetting
조건에 맞는 부분(관측치, 행)만 필터링: query()
조건에 맞도록 행을 재정렬: sort_values()
변수들과 함수들을 이용하여 새로운 변수를 생성: assign()
카테고리별로 나뉘어진 데이터에 대한 통계치를 생성: groupby(), agg(), apply()
On-time data for all flights that departed NYC (i.e. JFK, LGA or EWR) in 2013
# import the datasetflights_data = sm.datasets.get_rdataset("flights", "nycflights13")flights = flights_data.dataflights = flights.drop(columns="time_hour") # drop the "time_hour" column
# Select all columns except those from year to day (inclusive)# .isin(): includesflights.loc[:, ~flights.columns.isin(["year", "month", "day"])] # Boolean indexing
dep_time
sched_dep_time
dep_delay
arr_time
sched_arr_time
arr_delay
carrier
flight
tailnum
origin
dest
air_time
distance
hour
minute
0
517.00
515
2.00
830.00
819
11.00
UA
1545
N14228
EWR
IAH
227.00
1400
5
15
1
533.00
529
4.00
850.00
830
20.00
UA
1714
N24211
LGA
IAH
227.00
1416
5
29
2
542.00
540
2.00
923.00
850
33.00
AA
1141
N619AA
JFK
MIA
160.00
1089
5
40
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
336773
NaN
1210
NaN
NaN
1330
NaN
MQ
3461
N535MQ
LGA
BNA
NaN
764
12
10
336774
NaN
1159
NaN
NaN
1344
NaN
MQ
3572
N511MQ
LGA
CLE
NaN
419
11
59
336775
NaN
840
NaN
NaN
1020
NaN
MQ
3531
N839MQ
LGA
RDU
NaN
431
8
40
336776 rows × 15 columns
cols = [col for col in flights.columns if col notin ["year", "month", "day"]]flights[cols]
dep_time sched_dep_time dep_delay arr_time sched_arr_time \
0 517.00 515 2.00 830.00 819
1 533.00 529 4.00 850.00 830
2 542.00 540 2.00 923.00 850
... ... ... ... ... ...
336773 NaN 1210 NaN NaN 1330
336774 NaN 1159 NaN NaN 1344
336775 NaN 840 NaN NaN 1020
arr_delay carrier flight tailnum origin dest air_time distance \
0 11.00 UA 1545 N14228 EWR IAH 227.00 1400
1 20.00 UA 1714 N24211 LGA IAH 227.00 1416
2 33.00 AA 1141 N619AA JFK MIA 160.00 1089
... ... ... ... ... ... ... ... ...
336773 NaN MQ 3461 N535MQ LGA BNA NaN 764
336774 NaN MQ 3572 N511MQ LGA CLE NaN 419
336775 NaN MQ 3531 N839MQ LGA RDU NaN 431
hour minute
0 5 15
1 5 29
2 5 40
... ... ...
336773 12 10
336774 11 59
336775 8 40
[336776 rows x 15 columns]
Series/Index object의 method와 함께 특정 string을 기준으로 선택 (string method와는 구별) .str.contains(), .str.startswith(), .str.endswith() ; True/False
# Select all columns that begin with “dep”.flights.loc[:, flights.columns.str.startswith("dep")] # Boolean indexing
dep_time dep_delay
0 517.00 2.00
1 533.00 4.00
2 542.00 2.00
... ... ...
336773 NaN NaN
336774 NaN NaN
336775 NaN NaN
[336776 rows x 2 columns]
# Select all columns that are charactersflights.select_dtypes("object") # dtype: object, number, ...
carrier tailnum origin dest
0 UA N14228 EWR IAH
1 UA N24211 LGA IAH
2 AA N619AA JFK MIA
... ... ... ... ...
336773 MQ N535MQ LGA BNA
336774 MQ N511MQ LGA CLE
336775 MQ N839MQ LGA RDU
[336776 rows x 4 columns]
index selection: reindex
rename()
pd.DataFrame.rename
flights.rename( columns={"dep_time": "dep_t", "arr_time": "arr_t"}, # 첫번째 인자 index=# inplace=True: dataframe is updated)
year
month
day
dep_t
sched_dep_time
dep_delay
arr_t
sched_arr_time
arr_delay
carrier
flight
tailnum
origin
dest
air_time
distance
hour
minute
0
2013
1
1
517.00
515
2.00
830.00
819
11.00
UA
1545
N14228
EWR
IAH
227.00
1400
5
15
1
2013
1
1
533.00
529
4.00
850.00
830
20.00
UA
1714
N24211
LGA
IAH
227.00
1416
5
29
2
2013
1
1
542.00
540
2.00
923.00
850
33.00
AA
1141
N619AA
JFK
MIA
160.00
1089
5
40
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
336773
2013
9
30
NaN
1210
NaN
NaN
1330
NaN
MQ
3461
N535MQ
LGA
BNA
NaN
764
12
10
336774
2013
9
30
NaN
1159
NaN
NaN
1344
NaN
MQ
3572
N511MQ
LGA
CLE
NaN
419
11
59
336775
2013
9
30
NaN
840
NaN
NaN
1020
NaN
MQ
3531
N839MQ
LGA
RDU
NaN
431
8
40
336776 rows × 18 columns
Note
index를 rename할 수도 있음
flights.rename( index={0: "a", 1: "b"},).head(3)# year month day dep_time ...# a 2013 1 1 517.00 ...# b 2013 1 1 533.00 ...# 2 2013 1 1 542.00 ...
flights.rename(lambda x: x[:3], axis="columns")# yea mon day dep sch dep arr sch arr car fli tai ori ...# 0 2013 1 1 517.00 515 2.00 830.00 819 11.00 UA 1545 N14228 EWR # 1 2013 1 1 533.00 529 4.00 850.00 830 20.00 UA 1714 N24211 LGA # 2 2013 1 1 542.00 540 2.00 923.00 850 33.00 AA 1141 N619AA JFK # ...
assign()
cols = ["year", "month", "day", "distance", "air_time"] +\ [col for col in flights.columns if col.endswith("delay")] # string method .endswithflights_sml = flights[cols].copy()flights_sml
year month day distance air_time dep_delay arr_delay
0 2013 1 1 1400 227.00 2.00 11.00
1 2013 1 1 1416 227.00 4.00 20.00
2 2013 1 1 1089 160.00 2.00 33.00
... ... ... ... ... ... ... ...
336773 2013 9 30 764 NaN NaN NaN
336774 2013 9 30 419 NaN NaN NaN
336775 2013 9 30 431 NaN NaN NaN
[336776 rows x 7 columns]
# 새로 만들어진 변수는 맨 뒤로flights_sml.assign( gain=lambda x: x.dep_delay - x.arr_delay, # x: DataFrame, flights_sml speed=flights_sml["distance"] / flights_sml["air_time"] *60# 직접 DataFrame 참조할 수도 있음)
year month day distance air_time dep_delay arr_delay gain \
0 2013 1 1 1400 227.00 2.00 11.00 -9.00
1 2013 1 1 1416 227.00 4.00 20.00 -16.00
2 2013 1 1 1089 160.00 2.00 33.00 -31.00
... ... ... ... ... ... ... ... ...
336773 2013 9 30 764 NaN NaN NaN NaN
336774 2013 9 30 419 NaN NaN NaN NaN
336775 2013 9 30 431 NaN NaN NaN NaN
speed
0 370.04
1 374.27
2 408.38
... ...
336773 NaN
336774 NaN
336775 NaN
[336776 rows x 9 columns]
# 앞에서 만든 변수나 함수를 이용할 수 있음flights_sml.assign( gain=lambda x: x.dep_delay - x.arr_delay, hours=lambda x: x.air_time /60, gain_per_hour=lambda x: x.gain / x.hours, rounded=lambda x: np.round(x.gain_per_hour, 1) # use a numpy function)
year month day distance air_time dep_delay arr_delay gain \
0 2013 1 1 1400 227.00 2.00 11.00 -9.00
1 2013 1 1 1416 227.00 4.00 20.00 -16.00
2 2013 1 1 1089 160.00 2.00 33.00 -31.00
... ... ... ... ... ... ... ... ...
336773 2013 9 30 764 NaN NaN NaN NaN
336774 2013 9 30 419 NaN NaN NaN NaN
336775 2013 9 30 431 NaN NaN NaN NaN
hours gain_per_hour rounded
0 3.78 -2.38 -2.40
1 3.78 -4.23 -4.20
2 2.67 -11.62 -11.60
... ... ... ...
336773 NaN NaN NaN
336774 NaN NaN NaN
336775 NaN NaN NaN
[336776 rows x 11 columns]
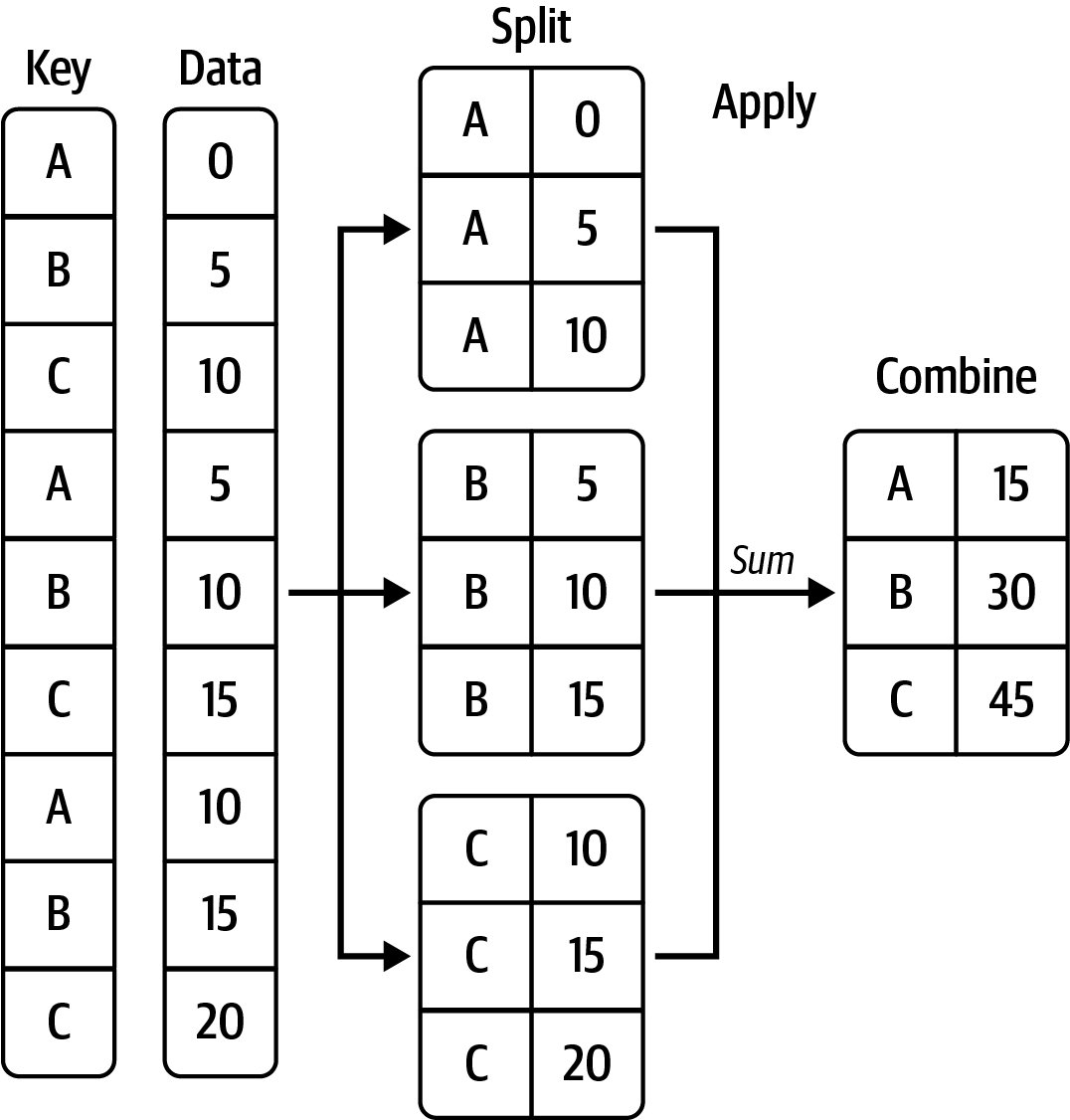
Aggregations: data transformation that produces scalar values from arrays
앞서 GroupBy object에 직접 stats function을 적용하였는데, agg()를 이용하여 더 확장, 일반화할 수 있음
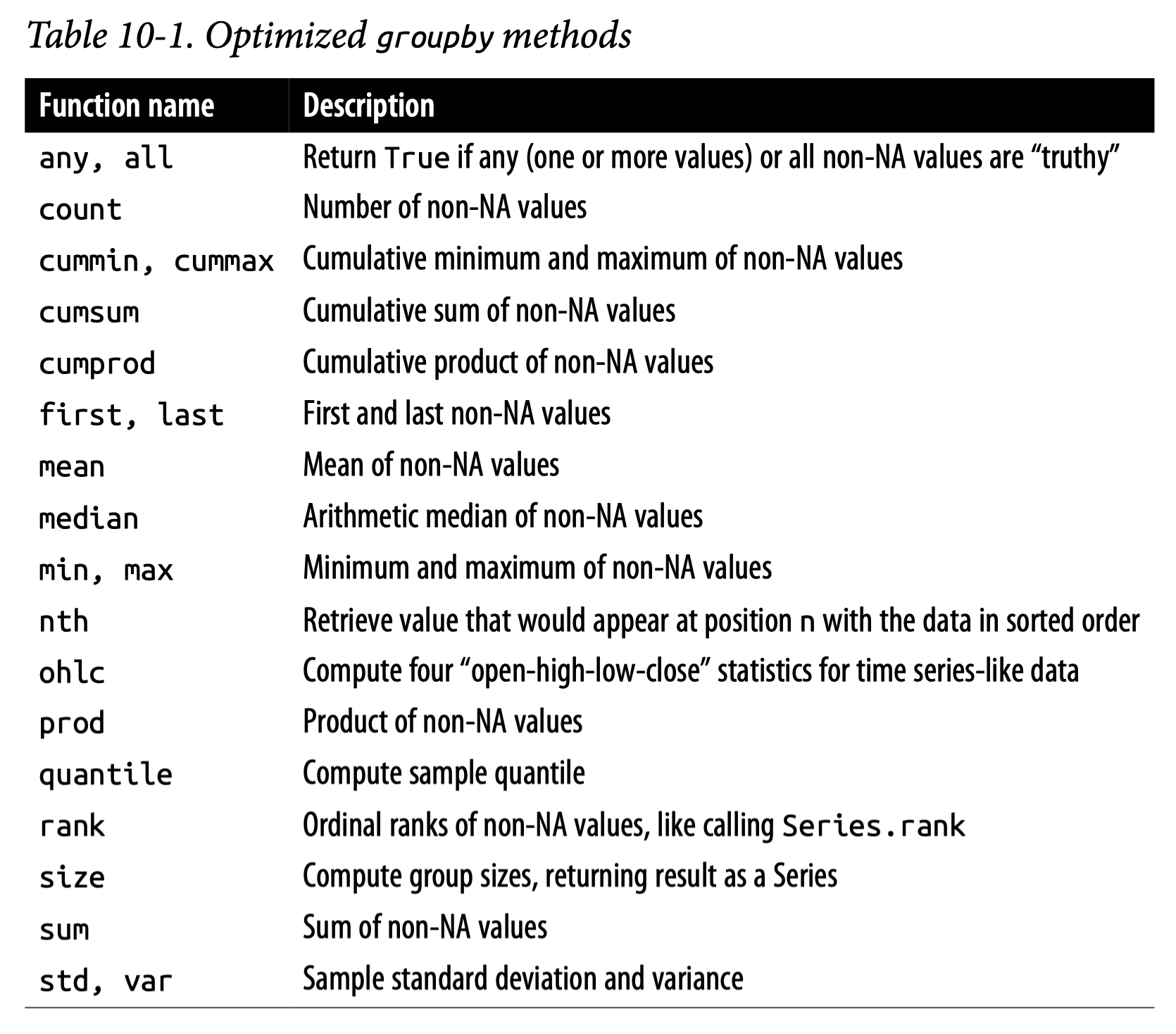
# 모두 동일flights_sml.groupby("month").mean()flights_sml.groupby("month").agg("mean") # function namesflights_sml.groupby("month").agg(np.mean) # numpy functionsflights_sml.groupby("month").agg(lambda x: x.sum() / x.count()) # general functions; not optimized!
앞서 group별로 통계치가 summary되어 원래 reduced 데이터프레임으로 변형됐다면, transform()은 group별로 얻은 통계치가 원래 데이터의 형태를 그대로 보존하면서 출력
만약, 전달되는 함수가 Series를 반환하려면, 동일한 사이즈로 반환되어야 함.
The most general-purpose GroupBy method is apply, which is the subject of this section. apply splits the object being manipulated into pieces, invokes the passed function on each piece, and then attempts to concatenate the pieces.
total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female No Sun Dinner 2 0.06
1 10.34 1.66 Male No Sun Dinner 3 0.16
2 21.01 3.50 Male No Sun Dinner 3 0.17
total_bill tip sex smoker day time size tip_pct
172 7.25 5.15 Male Yes Sun Dinner 2 0.71
178 9.60 4.00 Female Yes Sun Dinner 2 0.42
67 3.07 1.00 Female Yes Sat Dinner 1 0.33
232 11.61 3.39 Male No Sat Dinner 2 0.29
total_bill tip sex smoker day time size tip_pct
time day
Lunch Thur 197 43.11 5.00 Female Yes Thur Lunch 4 0.12
Fri 225 16.27 2.50 Female Yes Fri Lunch 2 0.15
Dinner Thur 243 18.78 3.00 Female No Thur Dinner 2 0.16
Fri 95 40.17 4.73 Male Yes Fri Dinner 4 0.12
Sat 170 50.81 10.00 Male Yes Sat Dinner 3 0.20
Sun 156 48.17 5.00 Male No Sun Dinner 6 0.10
GroupBy안에서 describe()와 같은 method를 적용하면, 사실 다음과 같은 shortcut임
total_bill tip
time
Lunch 17.17 2.73
Dinner 20.80 3.10
Important
적용되는 함수는 pandas object나 scalar value를 반환해야 함
Note
위에서 agg()에 custom function을 pass할 수 있지만, 일반적으로 훨씬 느리다고 했는데,
이는 numeric array에 apply() method를 사용할 때에도 해당됨.
가능하다면, apply()를 피하는 것이 실행 속도를 크게 높일 수 있음. (단, “string”에 적용될 때는 차이 없음)
Suppressing the Group Keys
tips.groupby("time", group_keys=False).apply(top)# total_bill tip sex smoker day time size tip_pct# 149 7.51 2.00 Male No Thur Lunch 2 0.27# 221 13.42 3.48 Female Yes Fri Lunch 2 0.26# 194 16.58 4.00 Male Yes Thur Lunch 2 0.24# ...
Hide warnings
import warningswarnings.filterwarnings("ignore")
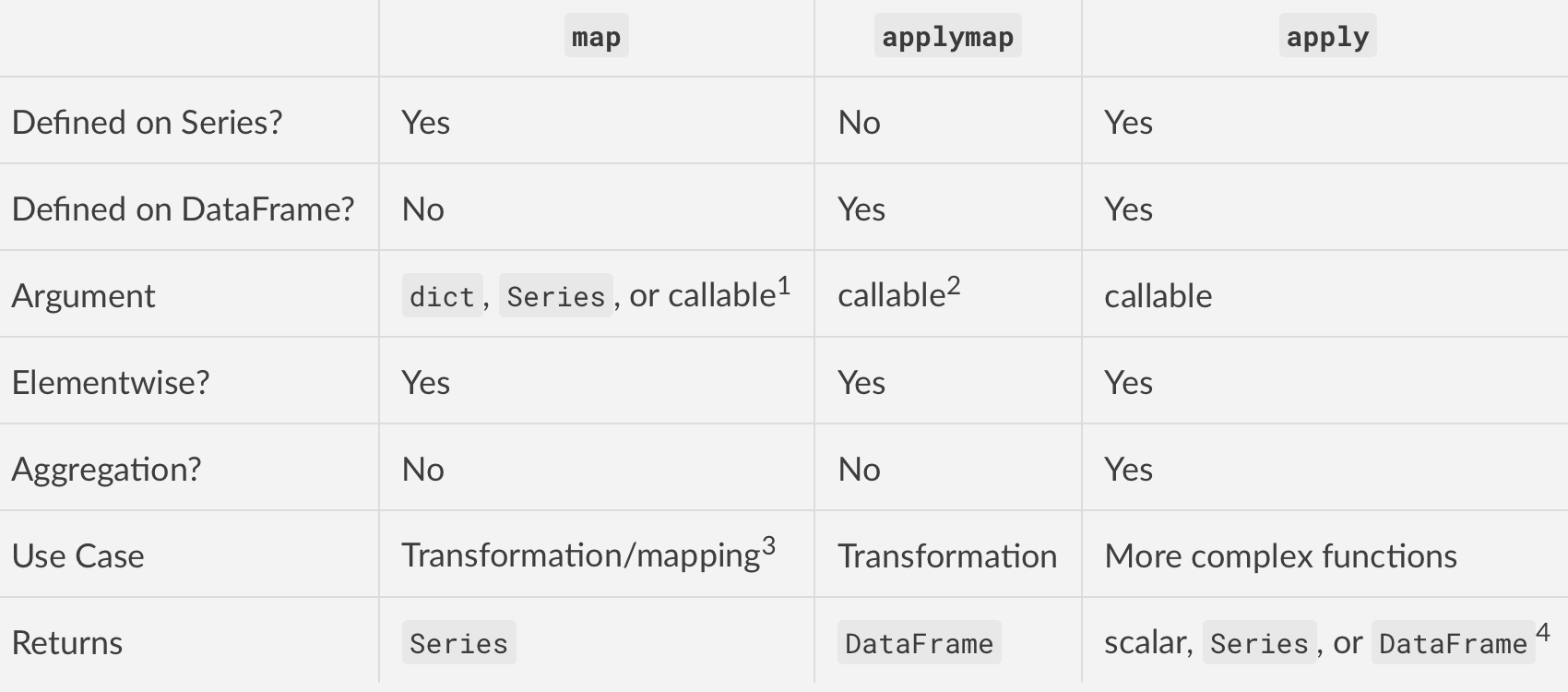
pandas method 비교
applymap: element-wise, DataFrame method
map: element-wise, Series method
apply: column/row-wise, DataFrame method, 또는 element-wise, Series method