# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# statisticsimport statsmodels.api as sm# pandas optionspd.set_option('mode.copy_on_write', True) # pandas 2.0pd.options.display.float_format ='{:.2f}'.format# pd.reset_option('display.float_format')pd.options.display.max_rows =7# max number of rows to display# NumPy optionsnp.set_printoptions(precision =2, suppress=True) # suppress scientific notation# For high resolution displayimport matplotlib_inlinematplotlib_inline.backend_inline.set_matplotlib_formats("retina")
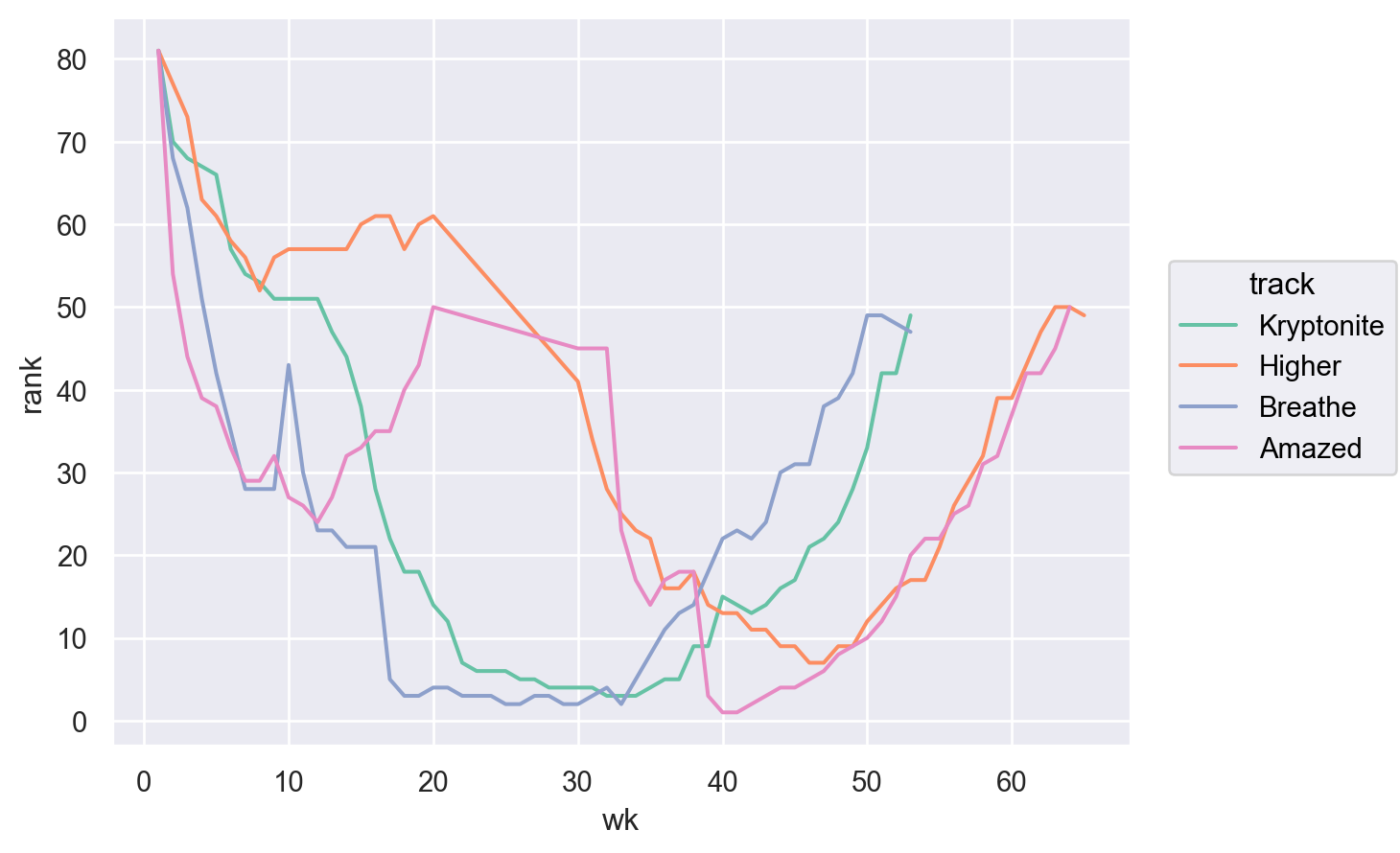
Song rankings for Billboard top 100 in the year 2000
각 곡이 차트에 진입한 날짜(date_entered)인 첫주(wk1)의 순위부터 78주(wk78)의 순위까지 기록되어 있습니다.
차트에서 빠진 경우 missing (NA)으로 표시되어 있습니다.
빌보드의 정책과 데이터 추출에 대해서 분명하지 않기 때문에 정확한 분석은 아닐 수 있습니다.
예를 들어, 20주 연속 차트에 있거나, 50위 밖으로 밀려난 경우 차트에서 제거된다고 합니다.
billboard = pd.read_csv("data/billboard.csv")billboard.head(5)
artist track date_entered wk1 wk2 wk3 wk4 \
0 2 Pac Baby Don't Cry (Keep... 2000-02-26 87 82.00 72.00 77.00
1 2Ge+her The Hardest Part Of ... 2000-09-02 91 87.00 92.00 NaN
2 3 Doors Down Kryptonite 2000-04-08 81 70.00 68.00 67.00
3 3 Doors Down Loser 2000-10-21 76 76.00 72.00 69.00
4 504 Boyz Wobble Wobble 2000-04-15 57 34.00 25.00 17.00
wk5 wk6 wk7 ... wk67 wk68 wk69 wk70 wk71 wk72 wk73 wk74 \
0 87.00 94.00 99.00 ... NaN NaN NaN NaN NaN NaN NaN NaN
1 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
2 66.00 57.00 54.00 ... NaN NaN NaN NaN NaN NaN NaN NaN
3 67.00 65.00 55.00 ... NaN NaN NaN NaN NaN NaN NaN NaN
4 17.00 31.00 36.00 ... NaN NaN NaN NaN NaN NaN NaN NaN
wk75 wk76
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
[5 rows x 79 columns]
총 몇 명의 가수(artist)가 차트에 있으며, 가수별로 몇 곡(track)이 차트에 들어있는지 알아보세요. (동명이인은 없다고 가정하고)
billboard.value_counts("artist")
artist
Jay-Z 5
Houston, Whitney 4
Dixie Chicks, The 4
..
Hollister, Dave 1
Hot Boys 1
matchbox twenty 1
Name: count, Length: 228, dtype: int64
곡명은 같지만, 가수가 다른 곡이 있는지 알아보고, 서로 다른 노래가 차트에 몇 개나 있는지 알아보세요.
billboard.value_counts("track")
track
Where I Wanna Be 2
Original Prankster 1
Separated 1
..
He Loves U Not 1
He Can't Love U 1
www.memory 1
Name: count, Length: 316, dtype: int64
artist track high
0 2 Pac Baby Don't Cry (Keep... 72.00
1 2Ge+her The Hardest Part Of ... 87.00
2 3 Doors Down Kryptonite 3.00
.. ... ... ...
314 Ying Yang Twins Whistle While You Tw... 74.00
315 Zombie Nation Kernkraft 400 99.00
316 matchbox twenty Bent 1.00
[317 rows x 3 columns]
rank wk
artist track
Aaliyah Try Again 8 59.00 1
4129 1.00 14
Aguilera, Christina Come On Over Baby (A... 11 57.00 1
... ... ..
Vertical Horizon Everything You Want 8225 1.00 26
matchbox twenty Bent 316 60.00 1
4120 1.00 13
[34 rows x 2 columns]
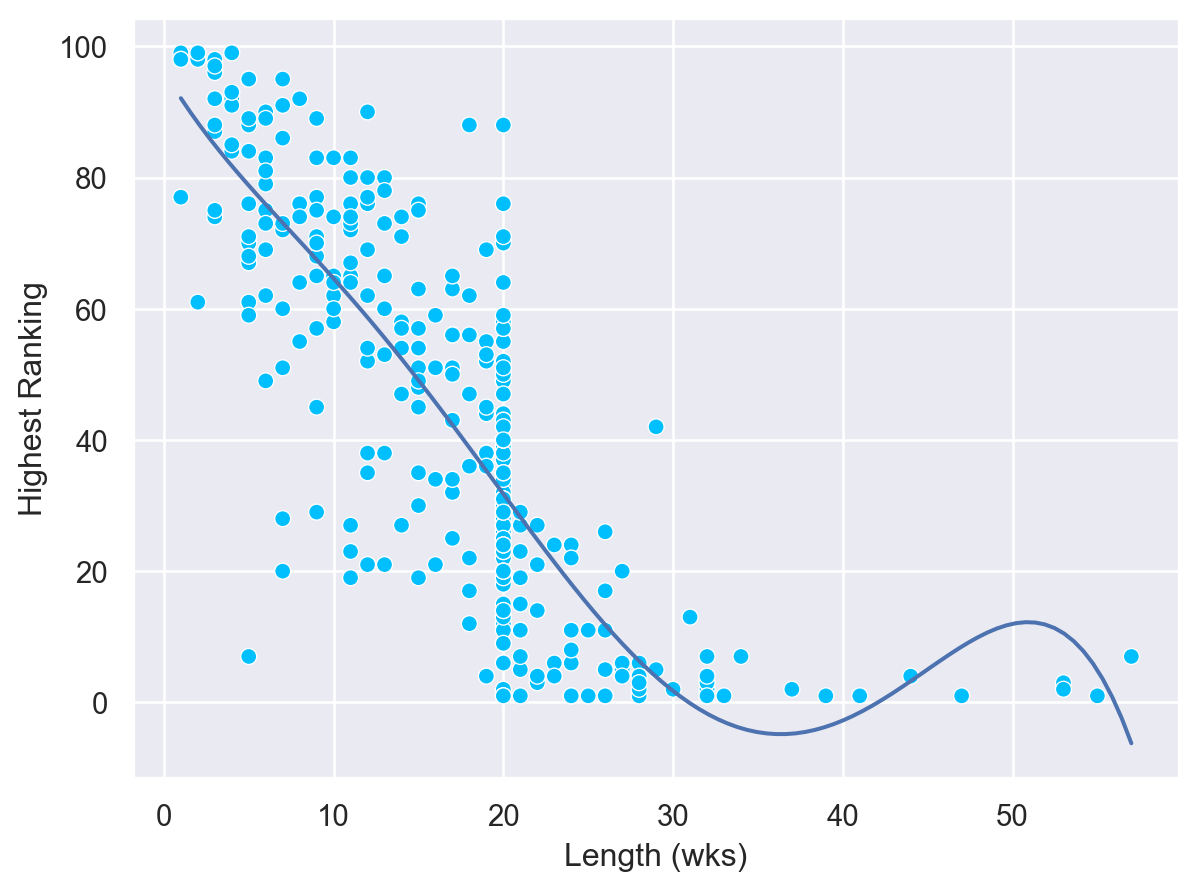
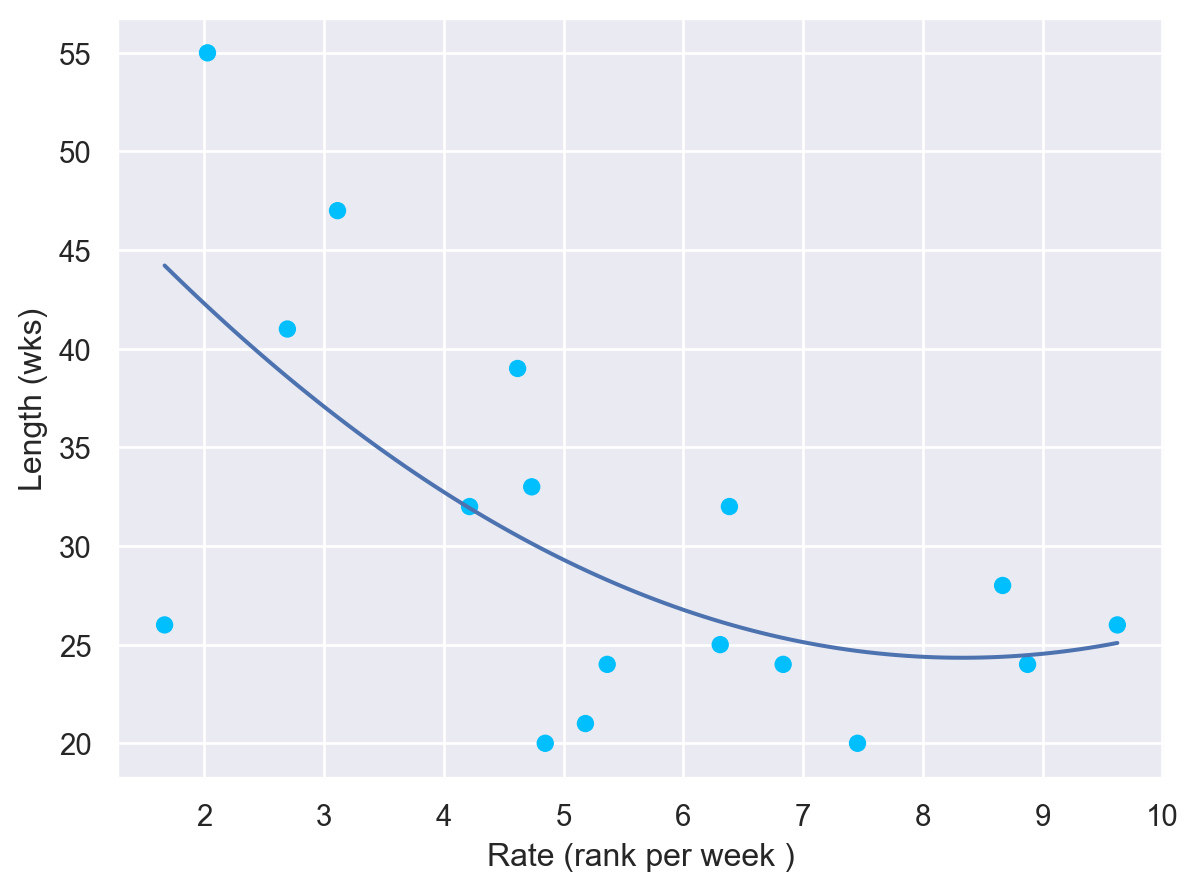
빠르게 1위가 된 곡일 수록 빠르게 차트에서 사라졌을까를 알아보기 위해, 7번의 결과를 이용해 다음과 같이 변형해보세요.
즉, 차트 진입시의 순위 정보와, 1위가 된 week의 정보만을 취해, 그 비율(rate)를 구하면, 얼마나 빠르게 1위가 되었는지 알 수 있습니다.
wk_rank.groupby(["artist", "track"]).max()
rank wk
artist track
Aaliyah Try Again 59.00 14
Aguilera, Christina Come On Over Baby (A... 57.00 11
What A Girl Wants 71.00 8
... ... ..
Sisqo Incomplete 77.00 8
Vertical Horizon Everything You Want 70.00 26
matchbox twenty Bent 60.00 13
[17 rows x 2 columns]
# 한 주에 몇 위 변동했는지 계산rates = ( wk_rank.groupby(["artist", "track"]) .max() .assign(rate=lambda x: x["rank"] / x["wk"]) .reset_index())rates
artist track rank wk rate
0 Aaliyah Try Again 59.00 14 4.21
1 Aguilera, Christina Come On Over Baby (A... 57.00 11 5.18
2 Aguilera, Christina What A Girl Wants 71.00 8 8.88
.. ... ... ... .. ...
14 Sisqo Incomplete 77.00 8 9.62
15 Vertical Horizon Everything You Want 70.00 26 2.69
16 matchbox twenty Bent 60.00 13 4.62
[17 rows x 5 columns]