# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# statisticsimport statsmodels.api as smimport statsmodels.formula.api as smf# pandas optionspd.set_option('mode.copy_on_write', True) # pandas 2.0pd.options.display.float_format ='{:.2f}'.format# pd.reset_option('display.float_format')pd.options.display.max_rows =7# max number of rows to display# NumPy optionsnp.set_printoptions(precision =2, suppress=True) # suppress scientific notation# For high resolution displayimport matplotlib_inlinematplotlib_inline.backend_inline.set_matplotlib_formats("retina")
bikeshare = pd.read_csv("../data/hour.csv")bikeshare_daily = pd.read_csv("../data/day.csv")def clean_data(df): df.rename({"dteday": "date", "cnt": "count"}, axis=1, inplace=True) df = df.assign( date=lambda x: pd.to_datetime(x["date"]), # datetime type으로 변환 year=lambda x: x["date"].dt.year.astype(str), # year 추출 day=lambda x: x["date"].dt.day_of_year, # day of the year 추출 month=lambda x: x["date"].dt.month_name().str[:3], # month 추출 wday=lambda x: x["date"].dt.day_name().str[:3], # 요일 추출 ) df["season"] = ( df["season"] .map({1: "winter", 2: "spring", 3: "summer", 4: "fall"}) # season을 문자열로 변환 .astype("category") # category type으로 변환 .cat.set_categories( ["winter", "spring", "summer", "fall"], ordered=True ) # 순서를 지정 )return dfbikes = clean_data(bikeshare)bikes_daily = clean_data(bikeshare_daily)
bikes_daily.head(3)
instant date season yr mnth holiday weekday workingday \
0 1 2011-01-01 winter 0 1 0 6 0
1 2 2011-01-02 winter 0 1 0 0 0
2 3 2011-01-03 winter 0 1 0 1 1
weathersit temp atemp hum windspeed casual registered count year \
0 2 0.34 0.36 0.81 0.16 331 654 985 2011
1 2 0.36 0.35 0.70 0.25 131 670 801 2011
2 1 0.20 0.19 0.44 0.25 120 1229 1349 2011
day month wday
0 1 Jan Sat
1 2 Jan Sun
2 3 Jan Mon
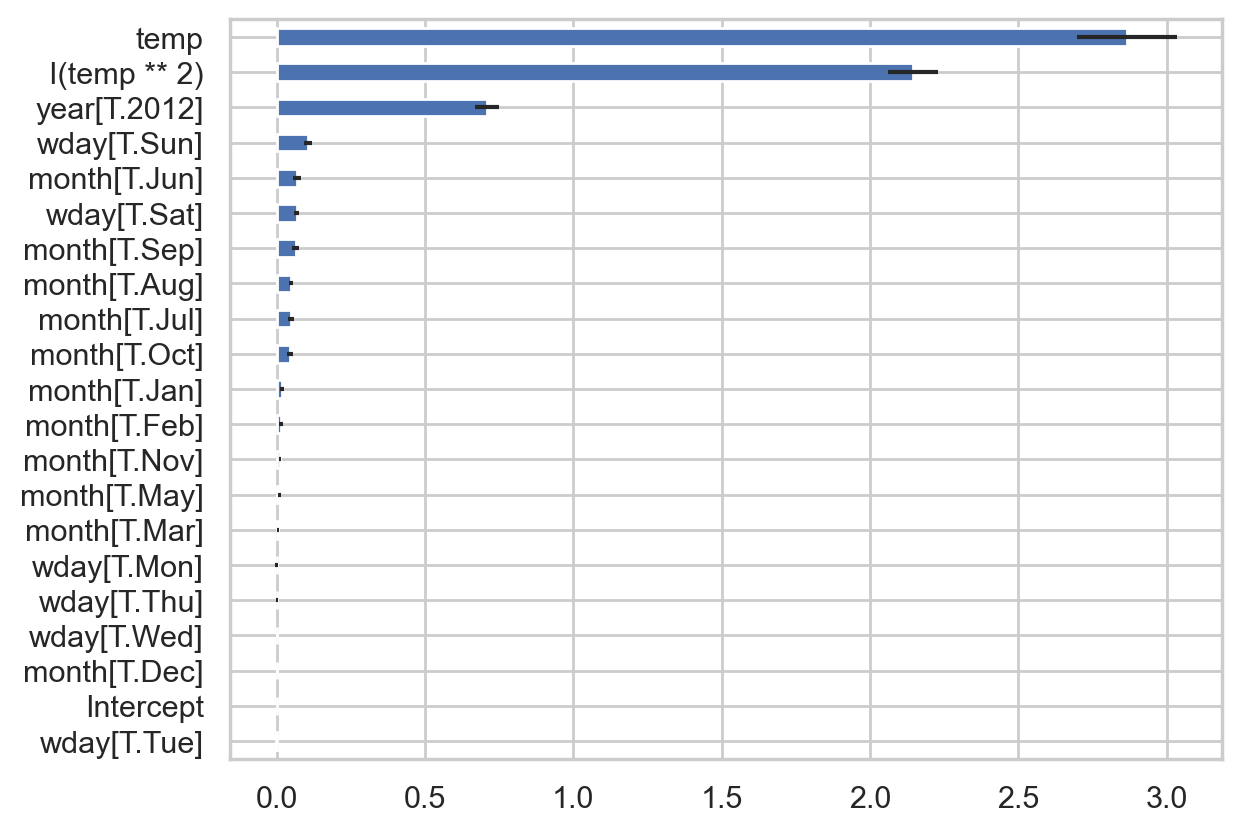
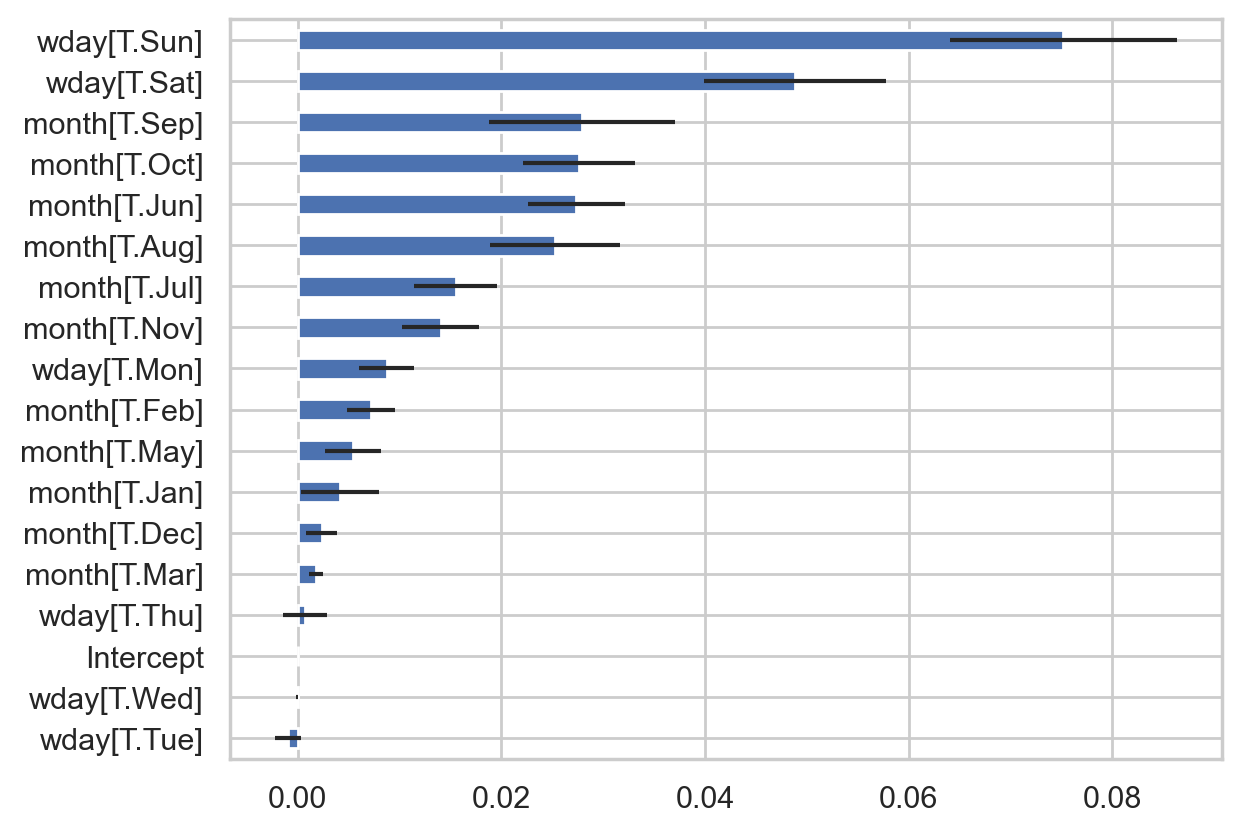
변수의 상대적 중요도
다양한 방식이 제안되어 있고 각각 한계가 있음. 예를 들어,
선형모형의 경우 표준화된 회귀계수(또는 T value), 부분 상관계수(partial, semi-partial correlation), 위계적 모형의 비교
from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom patsy import dmatricesy, X = dmatrices("registered ~ year + temp + I(temp**2) + month + wday", data=bikes_daily, return_type="dataframe")X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=123, test_size=0.5)lr = LinearRegression(fit_intercept=False)lr.fit(X_train, y_train)
LinearRegression(fit_intercept=False)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
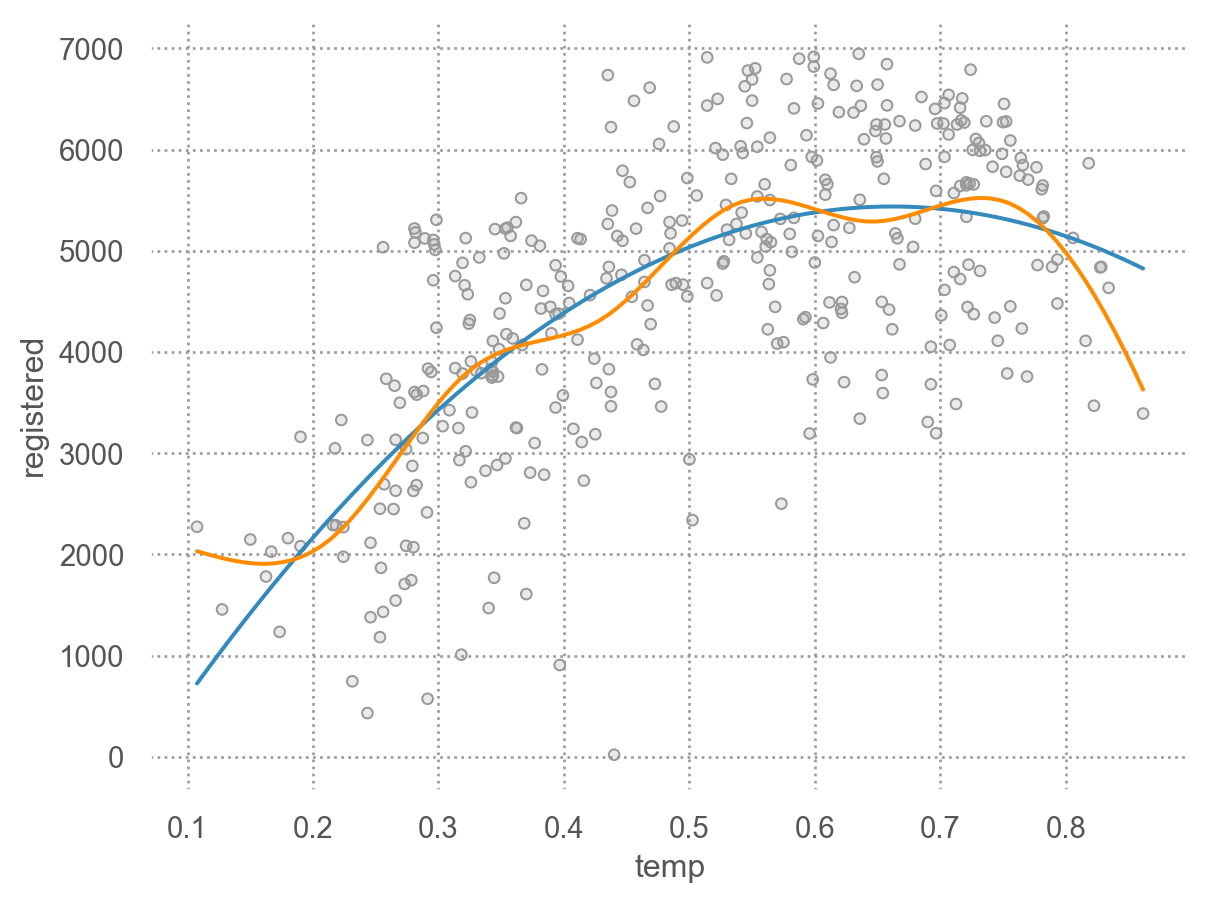
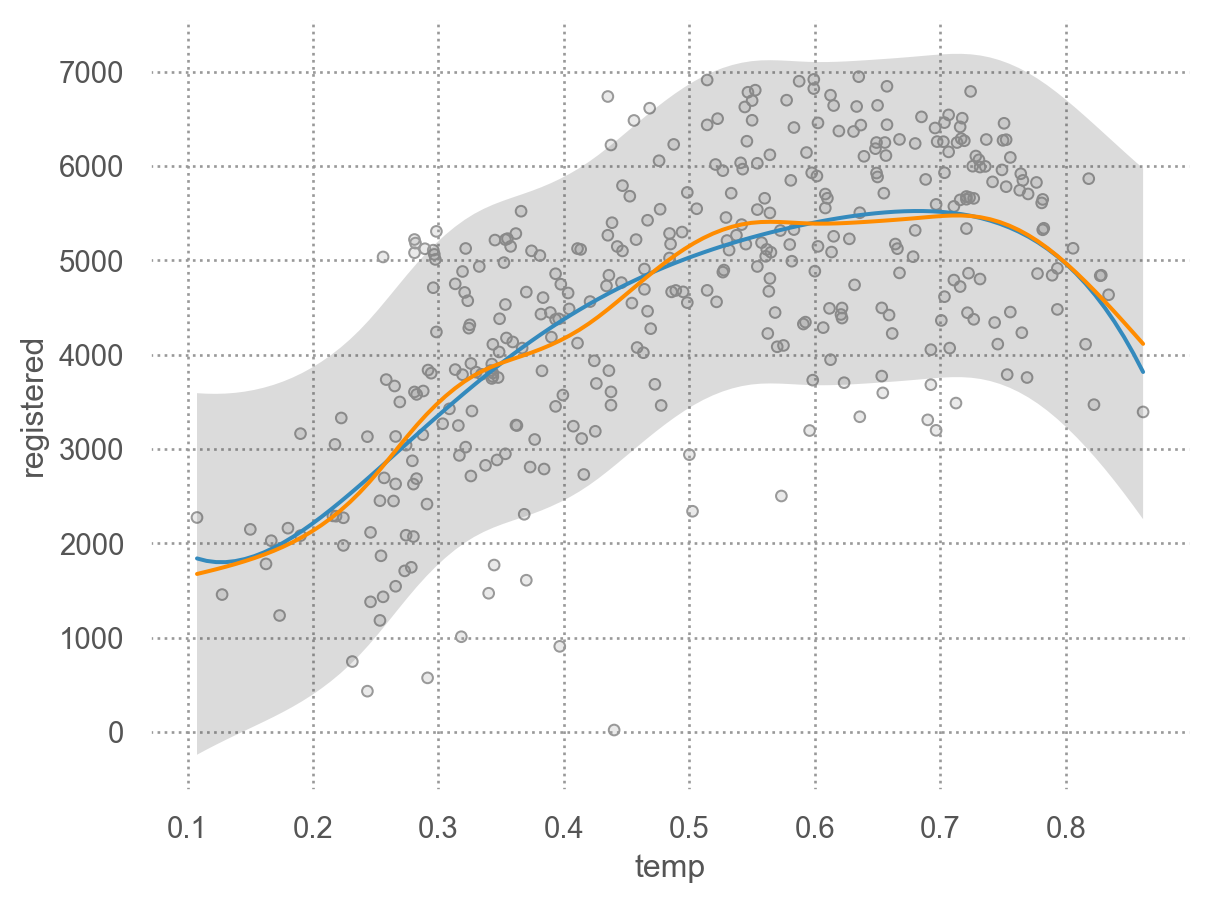
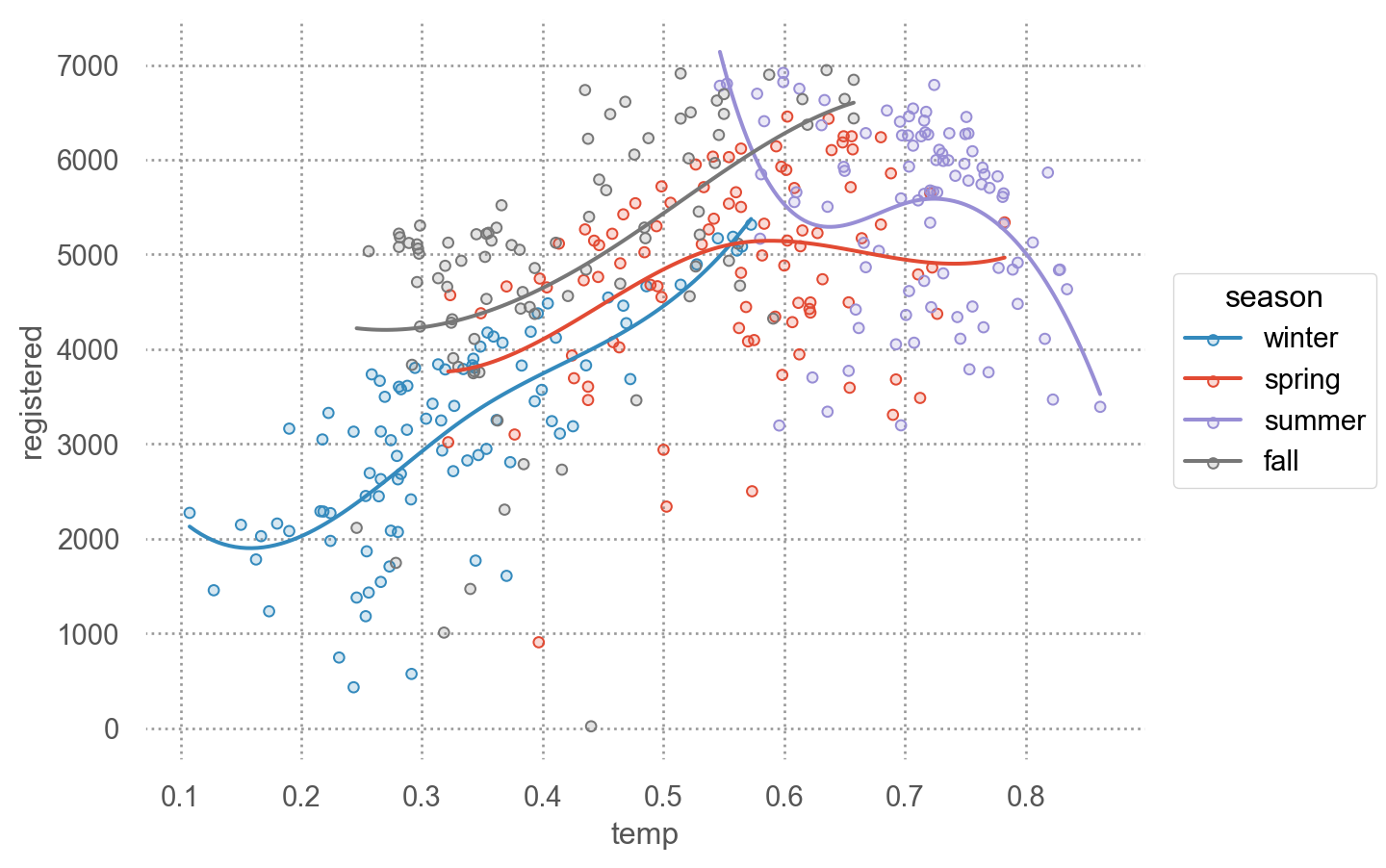
from __future__ import annotationsfrom dataclasses import dataclassimport numpy as npimport pandas as pdfrom seaborn._stats.base import Statfrom sklearn.preprocessing import SplineTransformerfrom sklearn.linear_model import LinearRegressionfrom sklearn.pipeline import make_pipeline@dataclassclass SplineFit(Stat):""" Fit a spline of the given n_knots and resample data onto predicted curve. """# This is a provisional class that is useful for building out functionality.# It may or may not change substantially in form or dissappear as we think# through the organization of the stats subpackage. n_knots: int=5 gridsize: int=100def _fit_predict(self, data): x = data["x"] y = data["y"]if x.nunique() <=self.n_knots:# TODO warn? xx = yy = []else: B_basis = SplineTransformer(n_knots=self.n_knots) lr = LinearRegression() spline = make_pipeline(B_basis, lr).fit(x.values.reshape(-1, 1), y) xx = np.linspace(x.min(), x.max(), self.gridsize) yy = spline.predict(xx.reshape(-1, 1))return pd.DataFrame(dict(x=xx, y=yy))# TODO we should have a way of identifying the method that will be applied# and then only define __call__ on a base-class of stats with this patterndef__call__(self, data, groupby, orient, scales):return ( groupby .apply(data.dropna(subset=["x", "y"]), self._fit_predict) )
# seaborn.objects의 객체로 변환so.Spline = SplineFit
( so.Plot(bikes_daily_2012, x='temp', y='registered', color="season") .add(so.Dots()) .add(so.Line(), so.Spline(3)) # Spline fit with 3 knots)