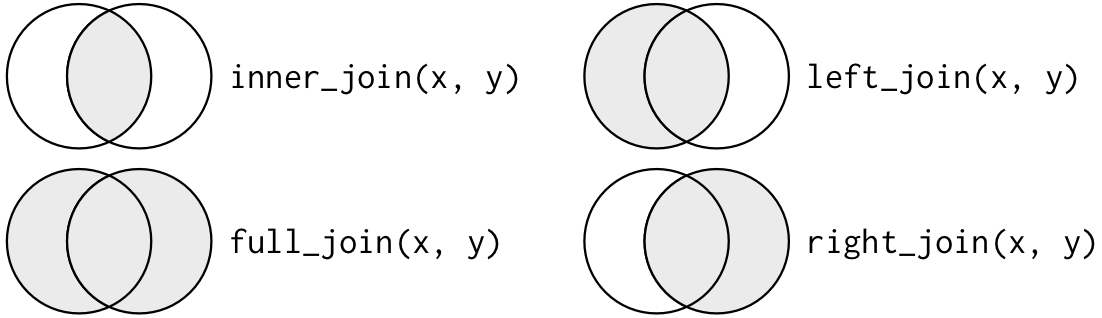# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# statisticsimport statsmodels.api as sm# pandas optionspd.set_option('mode.copy_on_write', True) # pandas 2.0pd.options.display.float_format ='{:.2f}'.format# pd.reset_option('display.float_format')pd.options.display.max_rows =7# max number of rows to display# NumPy optionsnp.set_printoptions(precision =2, suppress=True) # suppress scientific notation# For high resolution displayimport matplotlib_inlinematplotlib_inline.backend_inline.set_matplotlib_formats("retina")
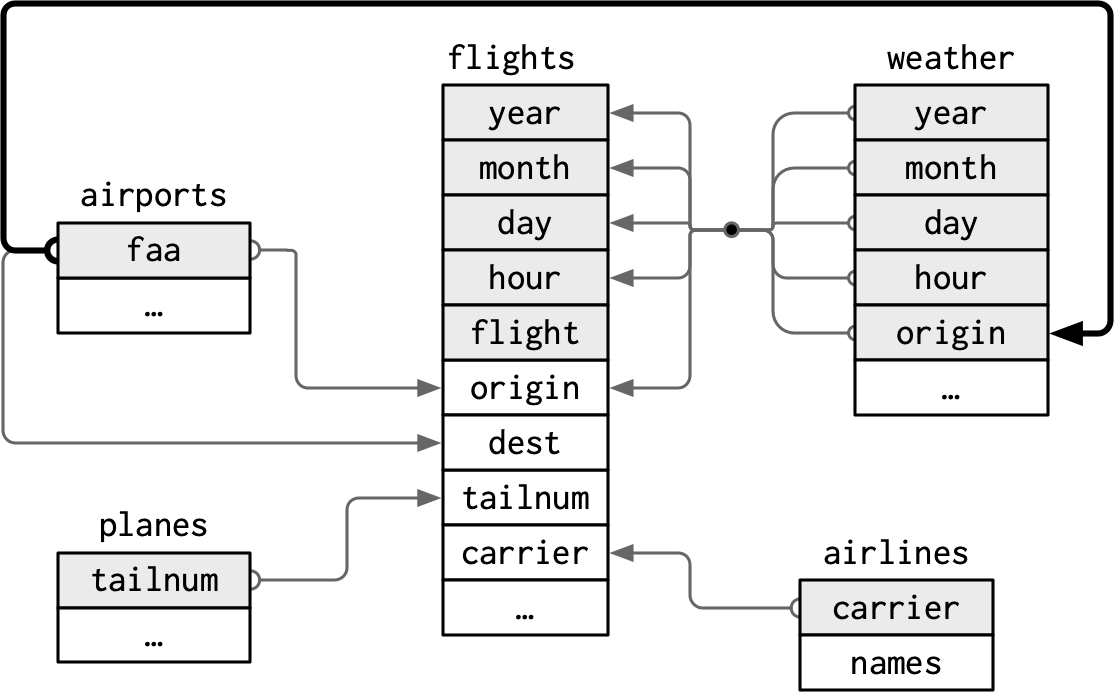
Relational Data
nycflights13
flights, airlines, airports, planes, weather are related
# Load the nycflight13 datasetflights = sm.datasets.get_rdataset("flights", "nycflights13").dataflights["time_hour"] = pd.to_datetime(flights["time_hour"], utc=False).dt.tz_convert("America/New_York") # convert to datetimeflights
year month day dep_time sched_dep_time dep_delay arr_time \
0 2013 1 1 517.00 515 2.00 830.00
1 2013 1 1 533.00 529 4.00 850.00
2 2013 1 1 542.00 540 2.00 923.00
... ... ... ... ... ... ... ...
336773 2013 9 30 NaN 1210 NaN NaN
336774 2013 9 30 NaN 1159 NaN NaN
336775 2013 9 30 NaN 840 NaN NaN
sched_arr_time arr_delay carrier flight tailnum origin dest \
0 819 11.00 UA 1545 N14228 EWR IAH
1 830 20.00 UA 1714 N24211 LGA IAH
2 850 33.00 AA 1141 N619AA JFK MIA
... ... ... ... ... ... ... ...
336773 1330 NaN MQ 3461 N535MQ LGA BNA
336774 1344 NaN MQ 3572 N511MQ LGA CLE
336775 1020 NaN MQ 3531 N839MQ LGA RDU
air_time distance hour minute time_hour
0 227.00 1400 5 15 2013-01-01 05:00:00-05:00
1 227.00 1416 5 29 2013-01-01 05:00:00-05:00
2 160.00 1089 5 40 2013-01-01 05:00:00-05:00
... ... ... ... ... ...
336773 NaN 764 12 10 2013-09-30 12:00:00-04:00
336774 NaN 419 11 59 2013-09-30 11:00:00-04:00
336775 NaN 431 8 40 2013-09-30 08:00:00-04:00
[336776 rows x 19 columns]
carrier name
0 9E Endeavor Air Inc.
1 AA American Airlines Inc.
2 AS Alaska Airlines Inc.
.. ... ...
13 VX Virgin America
14 WN Southwest Airlines Co.
15 YV Mesa Airlines Inc.
[16 rows x 2 columns]
year_x month day hour origin dest tailnum carrier year_y \
0 2013 1 1 5 EWR IAH N14228 UA 1999.00
1 2013 1 1 5 LGA IAH N24211 UA 1998.00
2 2013 1 1 5 JFK MIA N619AA AA 1990.00
type manufacturer model engines seats speed \
0 Fixed wing multi engine BOEING 737-824 2.00 149.00 NaN
1 Fixed wing multi engine BOEING 737-824 2.00 149.00 NaN
2 Fixed wing multi engine BOEING 757-223 2.00 178.00 NaN
engine
0 Turbo-fan
1 Turbo-fan
2 Turbo-fan
year month day hour origin dest tailnum carrier faa \
0 2013 1 1 5 EWR IAH N14228 UA IAH
1 2013 1 1 5 LGA IAH N24211 UA IAH
2 2013 1 1 5 JFK MIA N619AA AA MIA
3 2013 1 1 5 JFK BQN N804JB B6 NaN
4 2013 1 1 6 LGA ATL N668DN DL ATL
name lat lon alt tz dst \
0 George Bush Intercontinental 29.98 -95.34 97.00 -6.00 A
1 George Bush Intercontinental 29.98 -95.34 97.00 -6.00 A
2 Miami Intl 25.79 -80.29 8.00 -5.00 A
3 NaN NaN NaN NaN NaN NaN
4 Hartsfield Jackson Atlanta Intl 33.64 -84.43 1026.00 -5.00 A
tzone
0 America/Chicago
1 America/Chicago
2 America/New_York
3 NaN
4 America/New_York
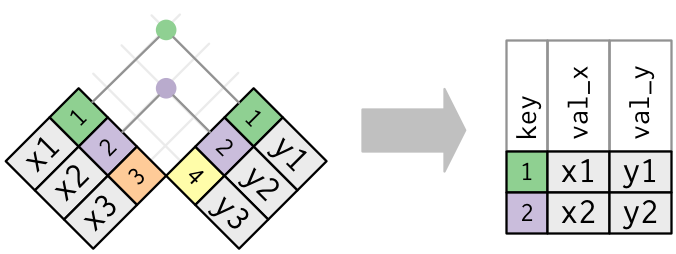
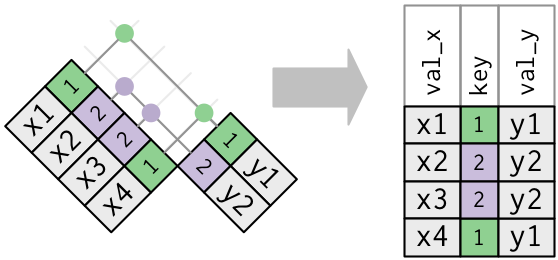
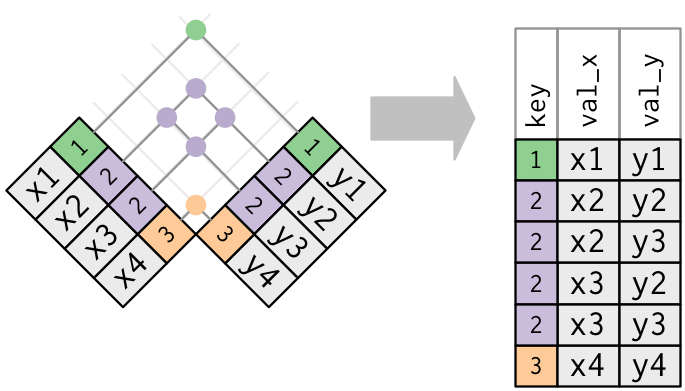
Start by identifying the variables that form the primary key in each table.
You should usually do this based on your understanding of the data, not empirically by looking for a combination of variables that give a unique identifier.
Check that none of the variables in the primary key are missing. If a value is missing then it can’t identify an observation!
Check that your foreign keys match primary keys in another table.
It’s common for keys not to match because of data entry errors. Fixing these is often a lot of work.
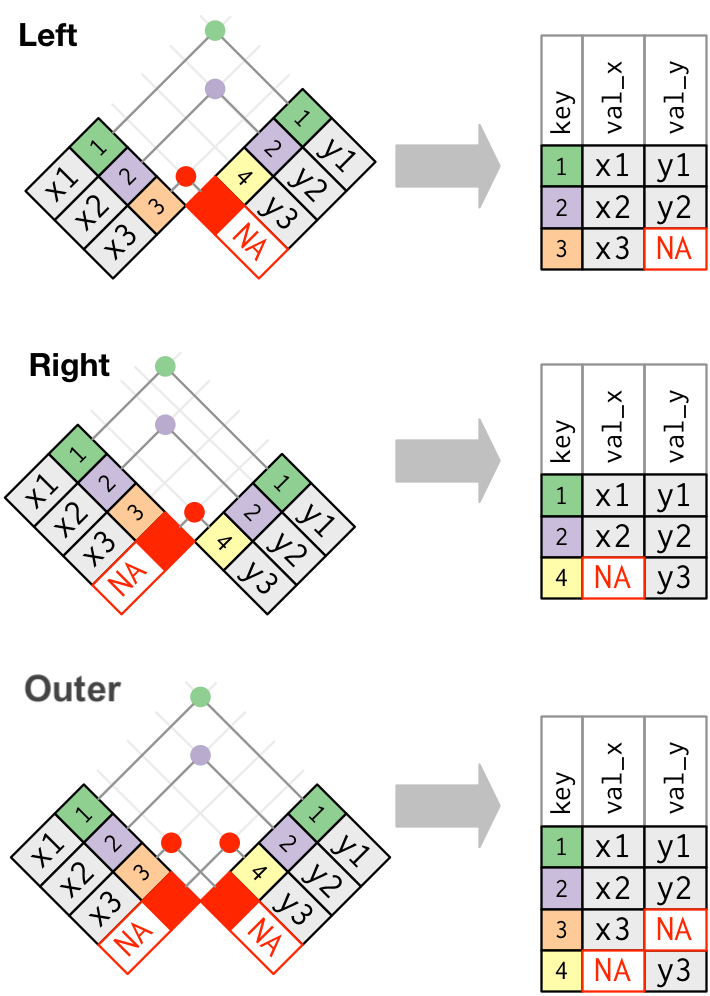
If you do have missing keys, you’ll need to be thoughtful about your use of inner vs. outer joins, carefully considering whether or not you want to drop rows that don’t have a match.