# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# statisticsimport statsmodels.api as sm# pandas optionspd.set_option('mode.copy_on_write', True) # pandas 2.0pd.options.display.float_format ='{:.2f}'.format# pd.reset_option('display.float_format')pd.options.display.max_rows =7# max number of rows to display# NumPy optionsnp.set_printoptions(precision =2, suppress=True) # suppress scientific notation# For high resolution displayimport matplotlib_inlinematplotlib_inline.backend_inline.set_matplotlib_formats("retina")
Flights to SFO
# import the dataflights = sm.datasets.get_rdataset('flights', 'nycflights13').data# convert the date column to a datetime objectflights["time_hour"] = pd.to_datetime(flights["time_hour"])# add a column for the day of the weekflights["dow"] = ( flights["time_hour"] .dt.day_name() .str[:3] .astype("category") .cat.set_categories(["Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"]))# add a column for the seasonflights["season"] = np.where(flights["month"].isin([6, 7]), "summer", "other month")
# filter out the flights to SFOsfo = flights.query('dest == "SFO" & arr_delay < 500').copy()
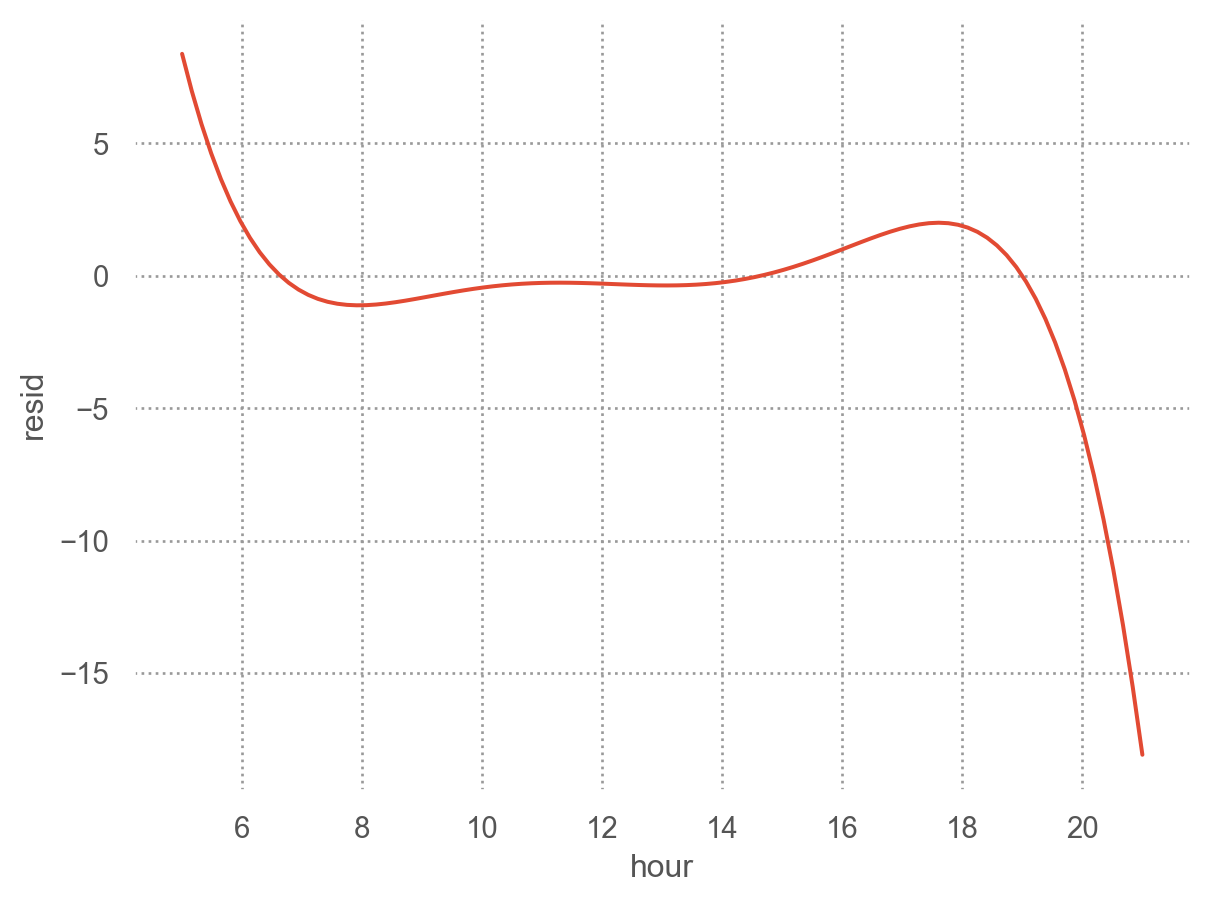
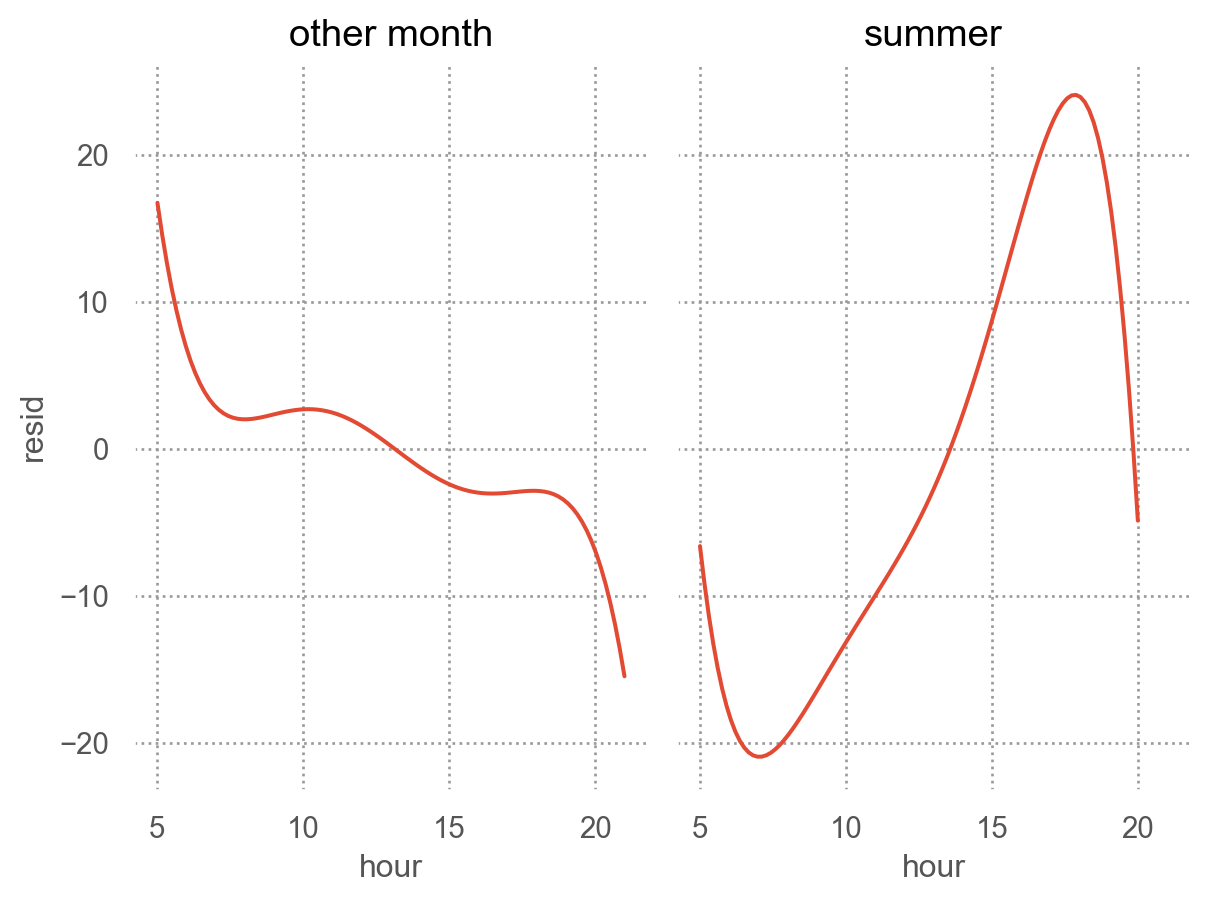
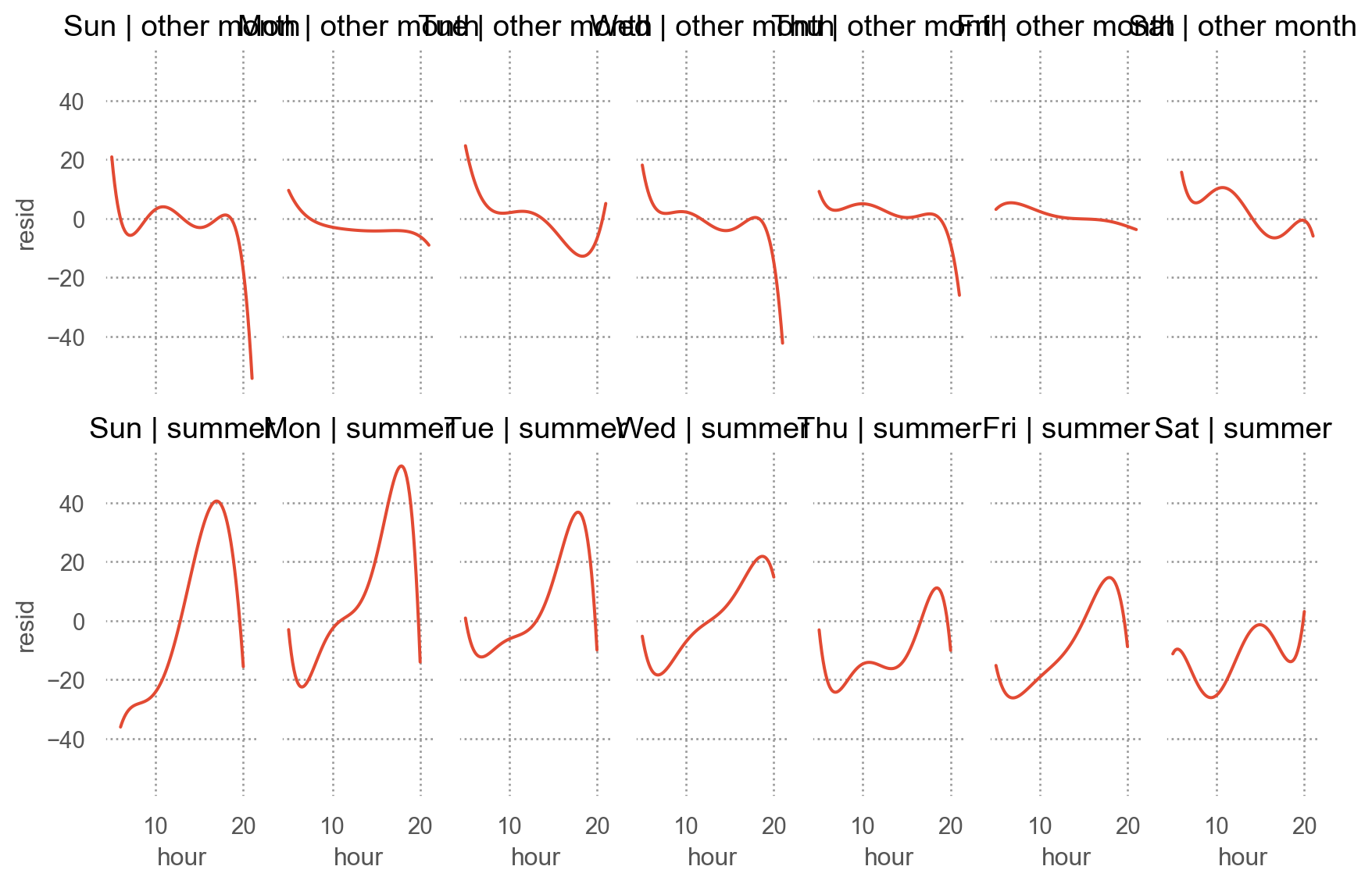
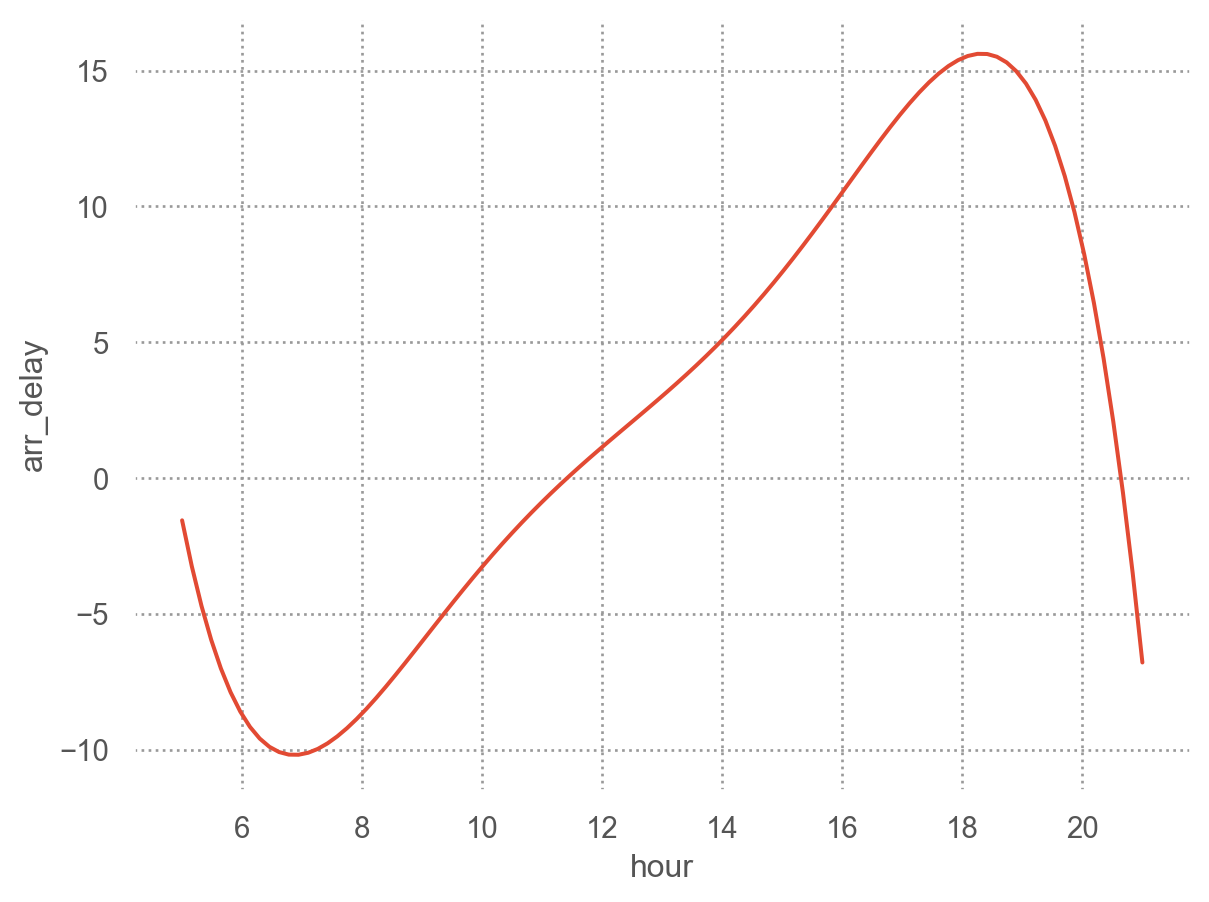
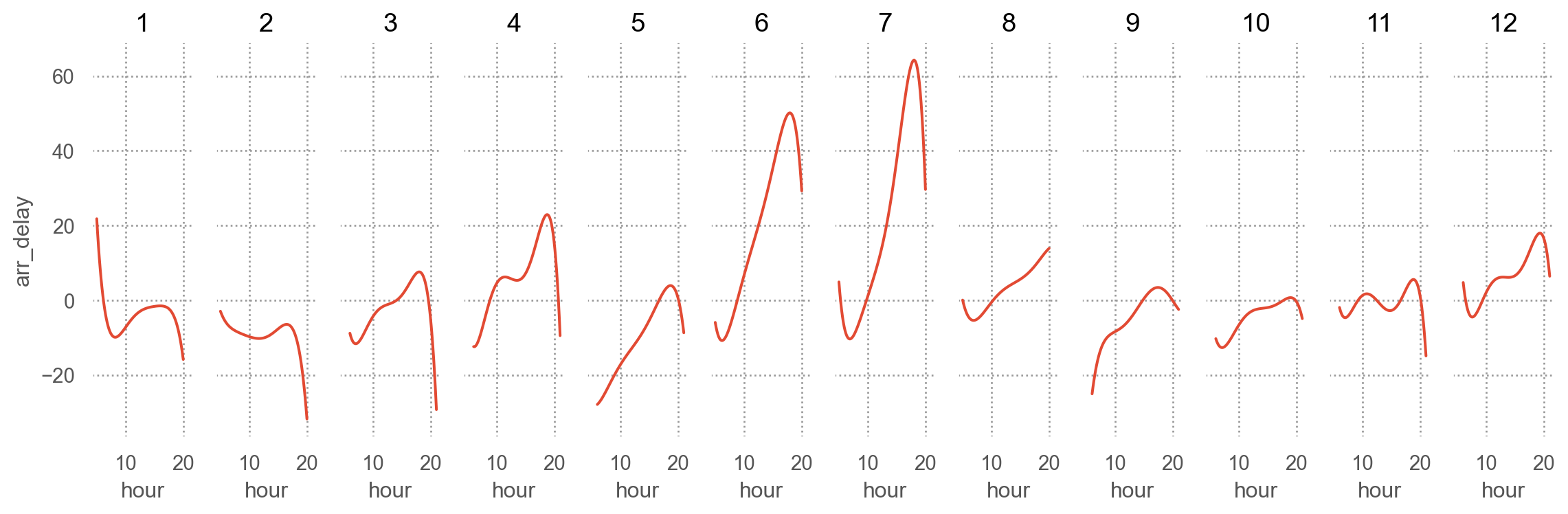
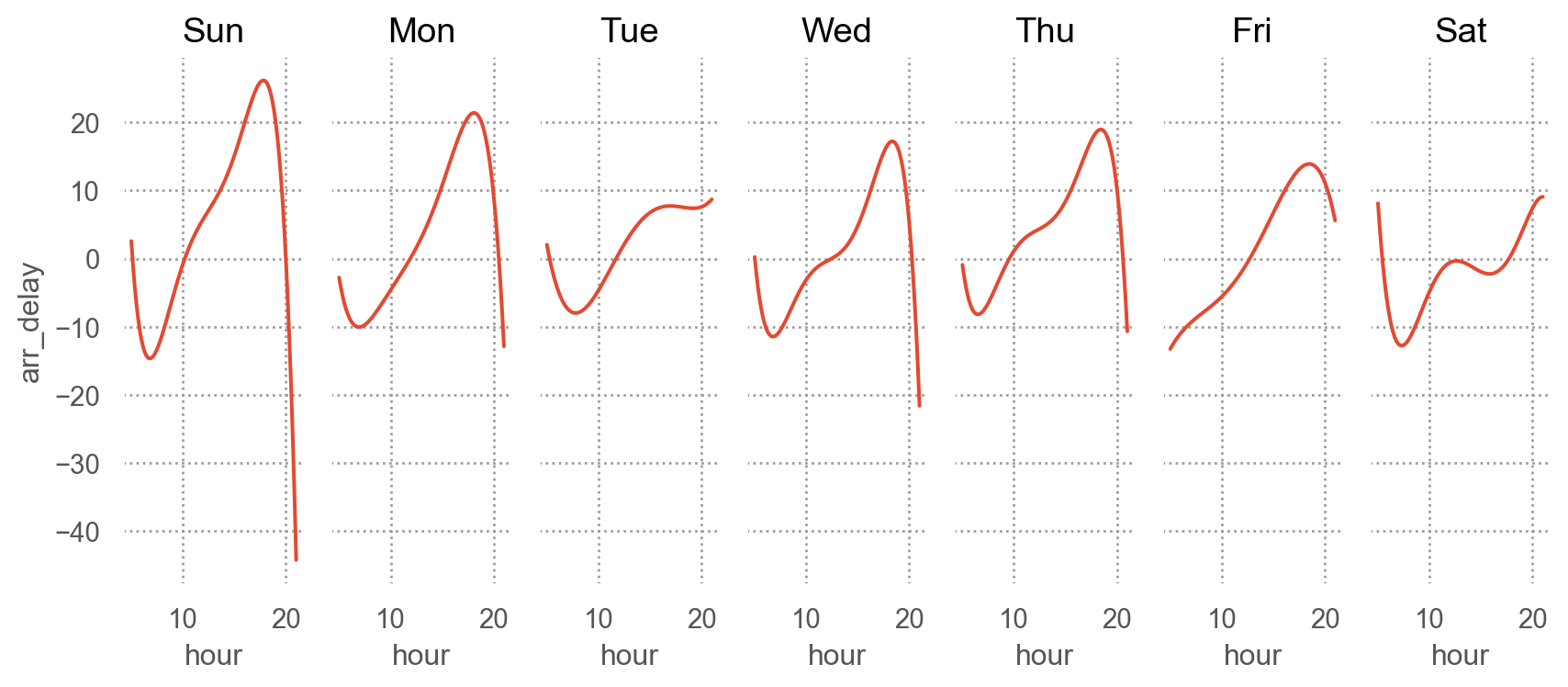
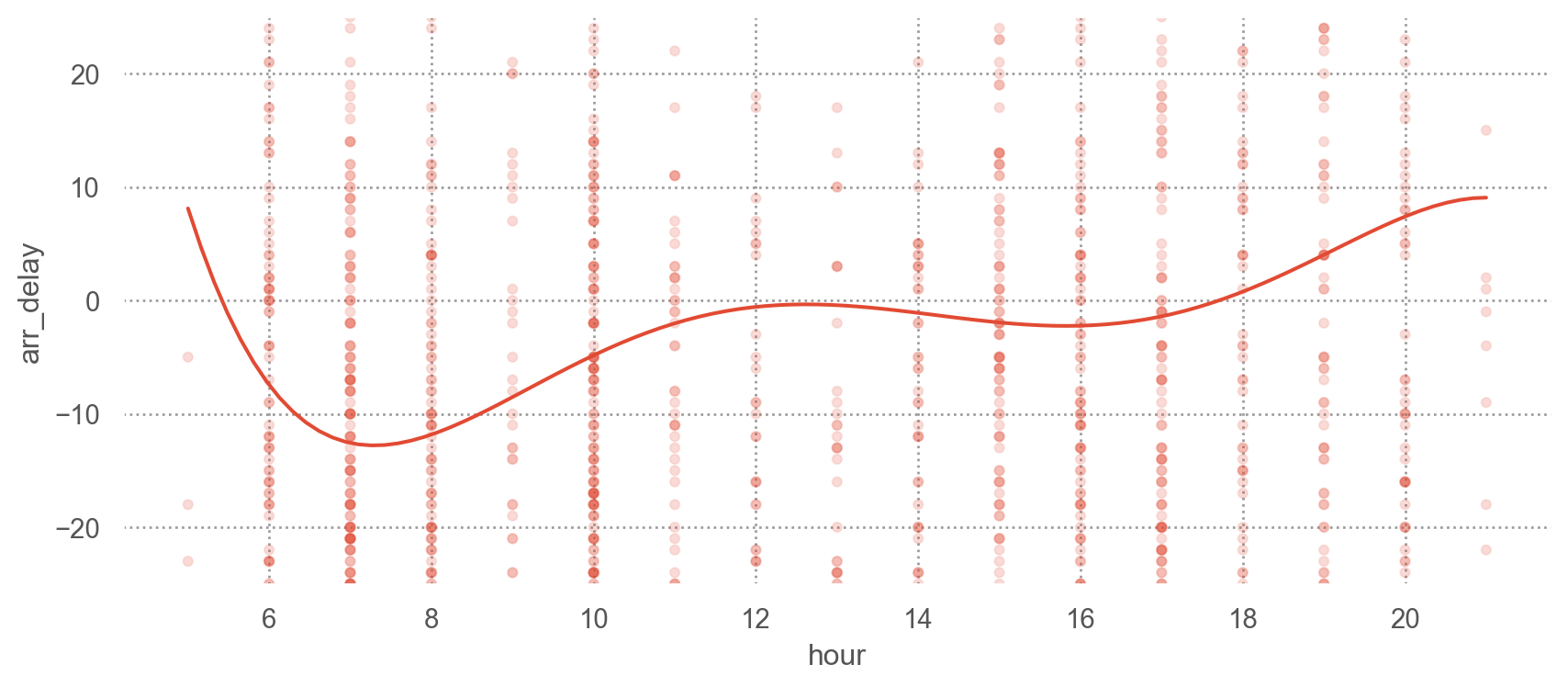
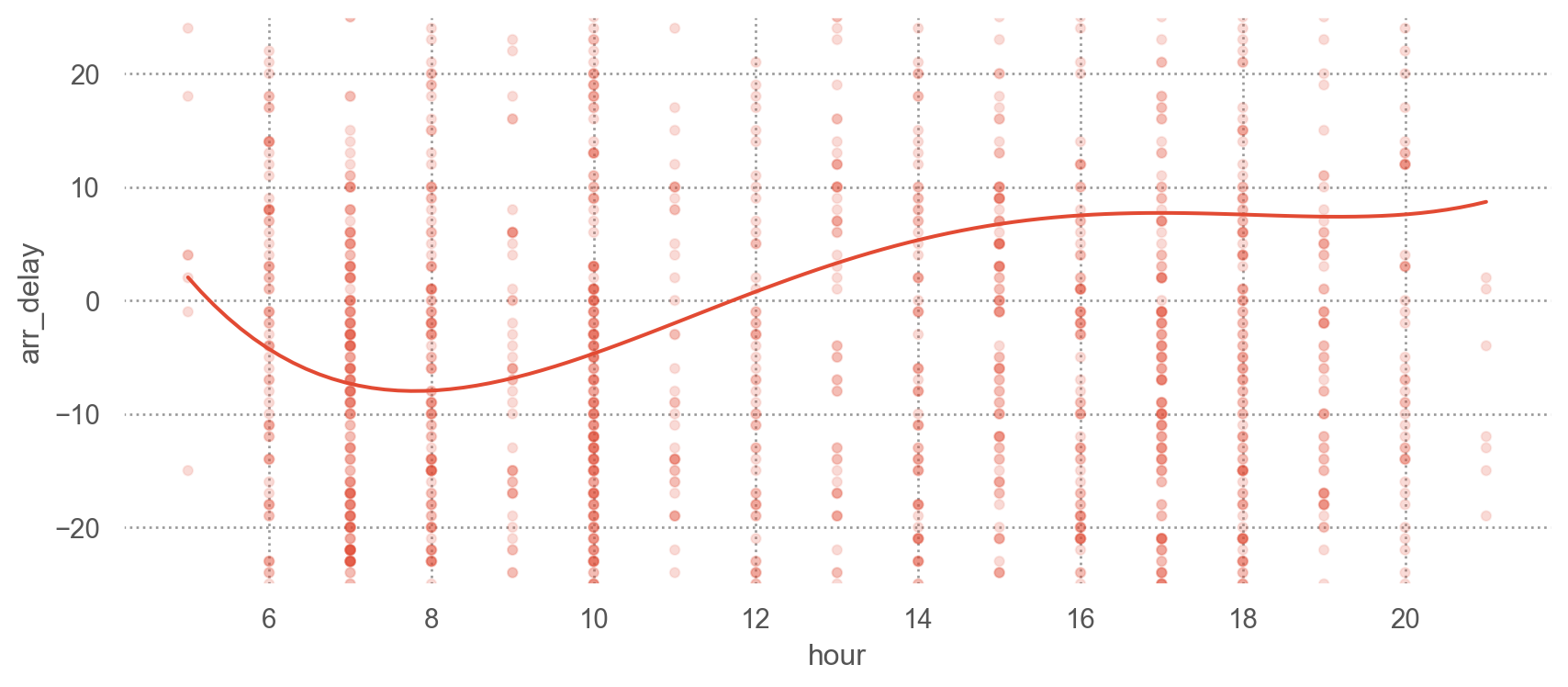
from statsmodels.formula.api import olsmod = ols("arr_delay ~ hour + origin + carrier + season + dow", data=sfo).fit()
the number of parameters: 172.0
Fold 1: Train R2: 0.19, Test R2: 0.12
Fold 2: Train R2: 0.18, Test R2: 0.13
Fold 3: Train R2: 0.18, Test R2: 0.17
Fold 4: Train R2: 0.17, Test R2: 0.18
Fold 5: Train R2: 0.18, Test R2: 0.16
Average Test R2: 0.15
Average AIC: 108788.40, Average BIC: 110044.81
cv_score(mod4)
the number of parameters: 34.0
Fold 1: Train R2: 0.14, Test R2: 0.11
Fold 2: Train R2: 0.14, Test R2: 0.12
Fold 3: Train R2: 0.13, Test R2: 0.14
Fold 4: Train R2: 0.13, Test R2: 0.14
Fold 5: Train R2: 0.14, Test R2: 0.14
Average Test R2: 0.13
Average AIC: 109047.00, Average BIC: 109301.19
cv_score(mod3)
the number of parameters: 14.0
Fold 1: Train R2: 0.12, Test R2: 0.09
Fold 2: Train R2: 0.12, Test R2: 0.11
Fold 3: Train R2: 0.12, Test R2: 0.13
Fold 4: Train R2: 0.12, Test R2: 0.13
Fold 5: Train R2: 0.12, Test R2: 0.13
Average Test R2: 0.12
Average AIC: 109229.17, Average BIC: 109338.10
the number of parameters: 424.0
Fold 1: Train R2: 0.21, Test R2: 0.10
Fold 2: Train R2: 0.21, Test R2: 0.12
Fold 3: Train R2: 0.20, Test R2: 0.14
Fold 4: Train R2: 0.20, Test R2: 0.16
Fold 5: Train R2: 0.20, Test R2: 0.15
Average Test R2: 0.14
Average AIC: 108957.71, Average BIC: 112044.26