# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# statisticsimport statsmodels.api as sm# pandas optionspd.set_option('mode.copy_on_write', True) # pandas 2.0pd.options.display.float_format ='{:.2f}'.format# pd.reset_option('display.float_format')pd.options.display.max_rows =7# max number of rows to display# NumPy optionsnp.set_printoptions(precision =2, suppress=True) # suppress scientific notation# For high resolution displayimport matplotlib_inlinematplotlib_inline.backend_inline.set_matplotlib_formats("retina")
Q1
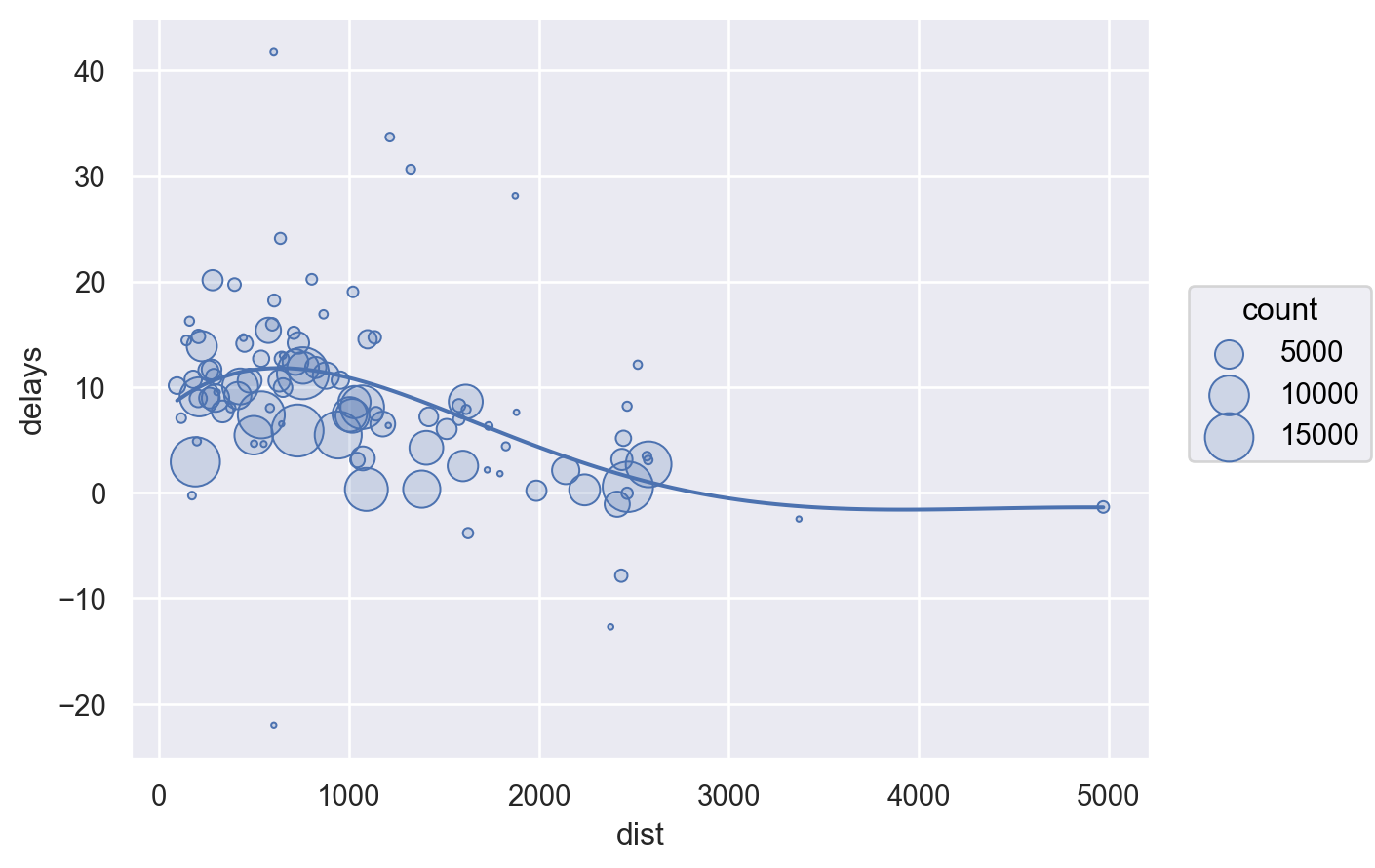
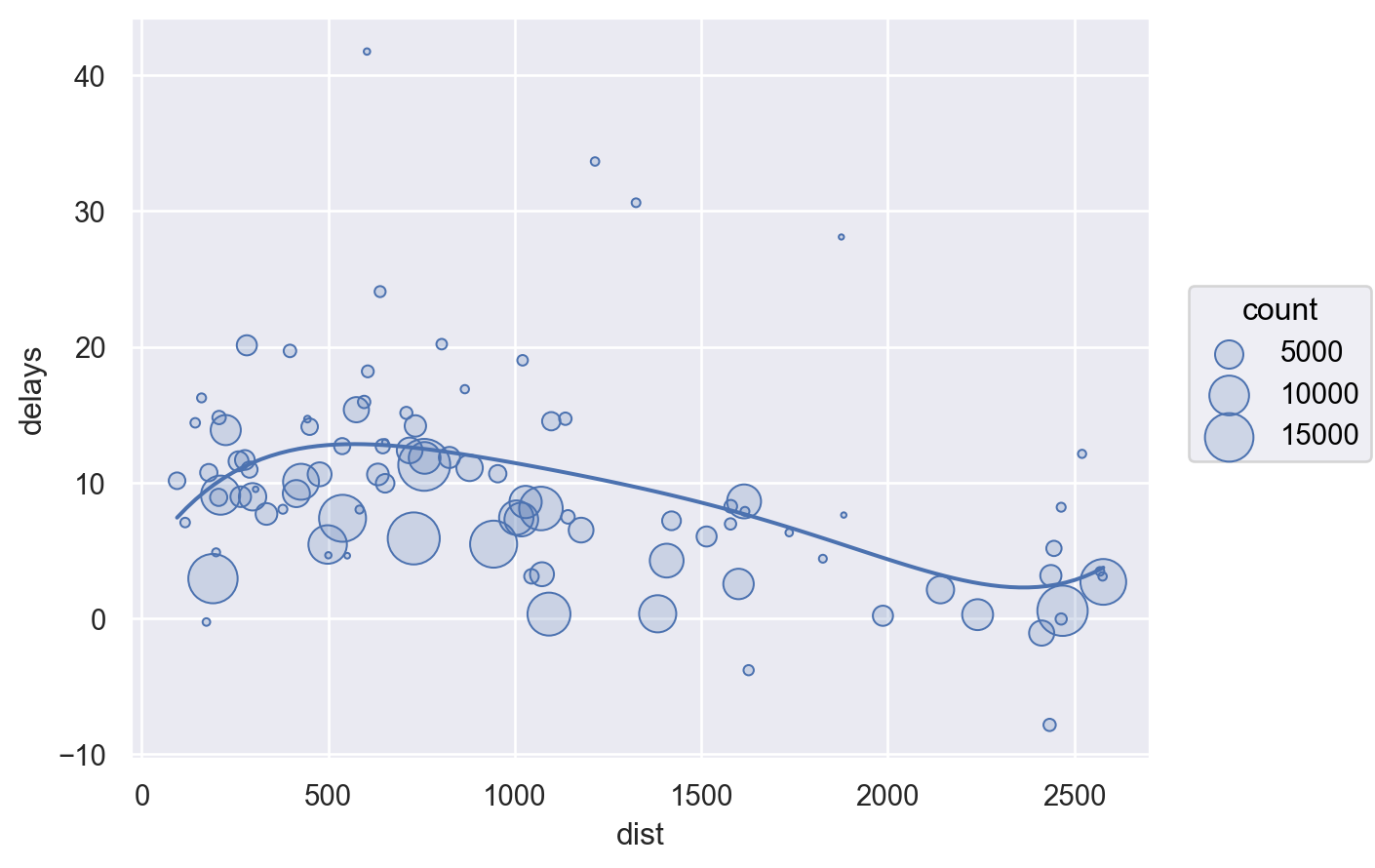
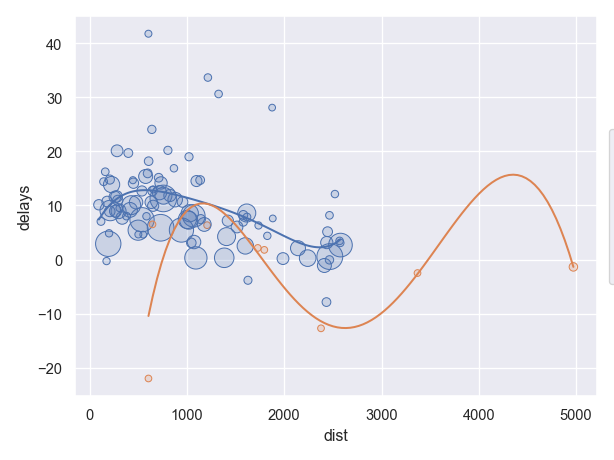
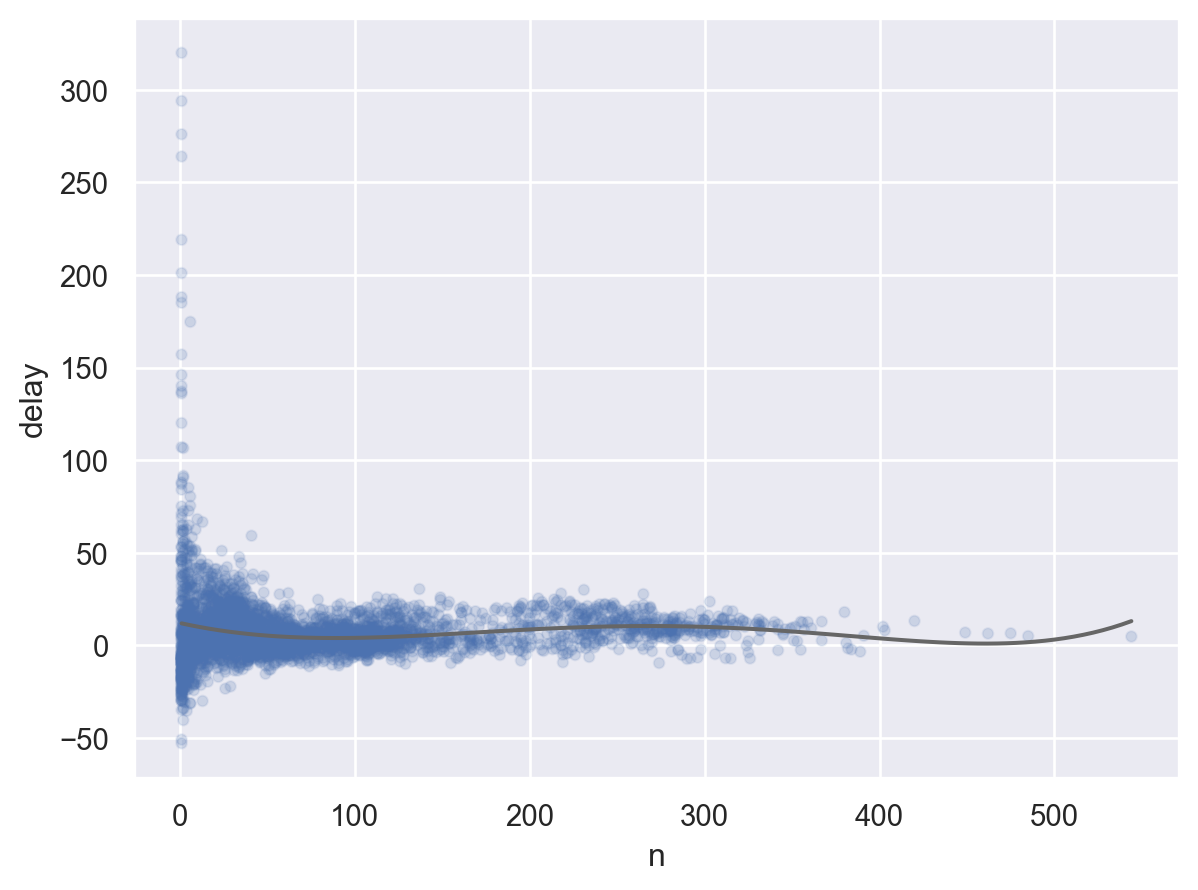
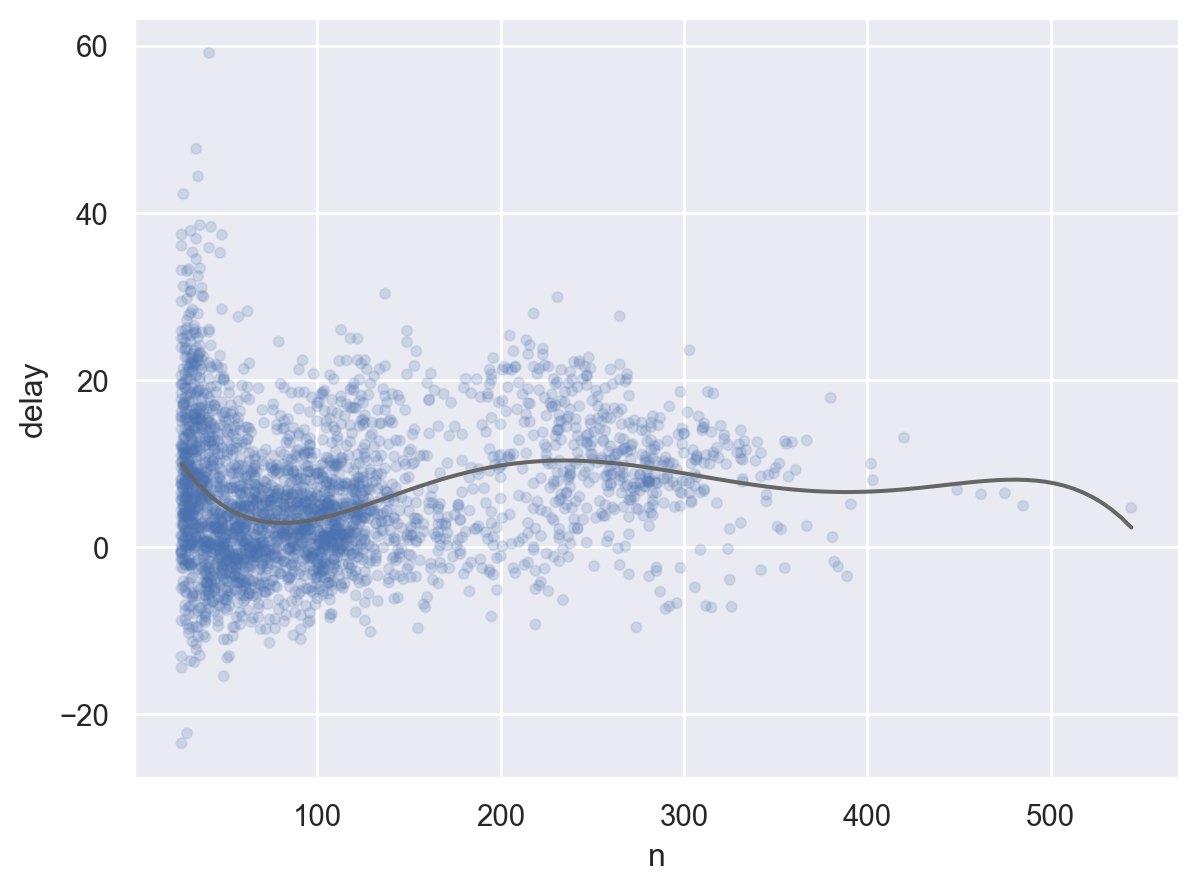
각 도착지에 따른 비행거리(distance)와 도착지연시간(arr_delay)와의 관계를 알아보고자 함.
Group flights by destination.
Summarise to compute distance, average delay, and number of flights.
Filter to remove noisy points and Honolulu airport, which is almost twice as far away as the next closest airport.
# Load the nycflight13 datasetflights = sm.datasets.get_rdataset("flights", "nycflights13").data.drop(columns="time_hour")
# grouping by destinationsby_dest = flights.groupby("dest")
playerID yearID stint teamID lgID G G_batting AB R \
0 aardsda01 2004 1 SFN NL 11 11 0.00 0.00
1 aardsda01 2006 1 CHN NL 45 43 2.00 0.00
2 aardsda01 2007 1 CHA AL 25 2 0.00 0.00
... ... ... ... ... ... ... ... ... ...
95192 zwilldu01 1914 1 CHF FL 154 154 592.00 91.00
95193 zwilldu01 1915 1 CHF FL 150 150 548.00 65.00
95194 zwilldu01 1916 1 CHN NL 35 35 53.00 4.00
H ... SB CS BB SO IBB HBP SH SF GIDP G_old
0 0.00 ... 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11.00
1 0.00 ... 0.00 0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 45.00
2 0.00 ... 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00
... ... ... ... ... ... ... ... ... ... ... ... ...
95192 185.00 ... 21.00 NaN 46.00 68.00 NaN 1.00 10.00 NaN NaN 154.00
95193 157.00 ... 24.00 NaN 67.00 65.00 NaN 2.00 18.00 NaN NaN 150.00
95194 6.00 ... 0.00 NaN 4.00 6.00 NaN 0.00 2.00 NaN NaN 35.00
[95195 rows x 24 columns]
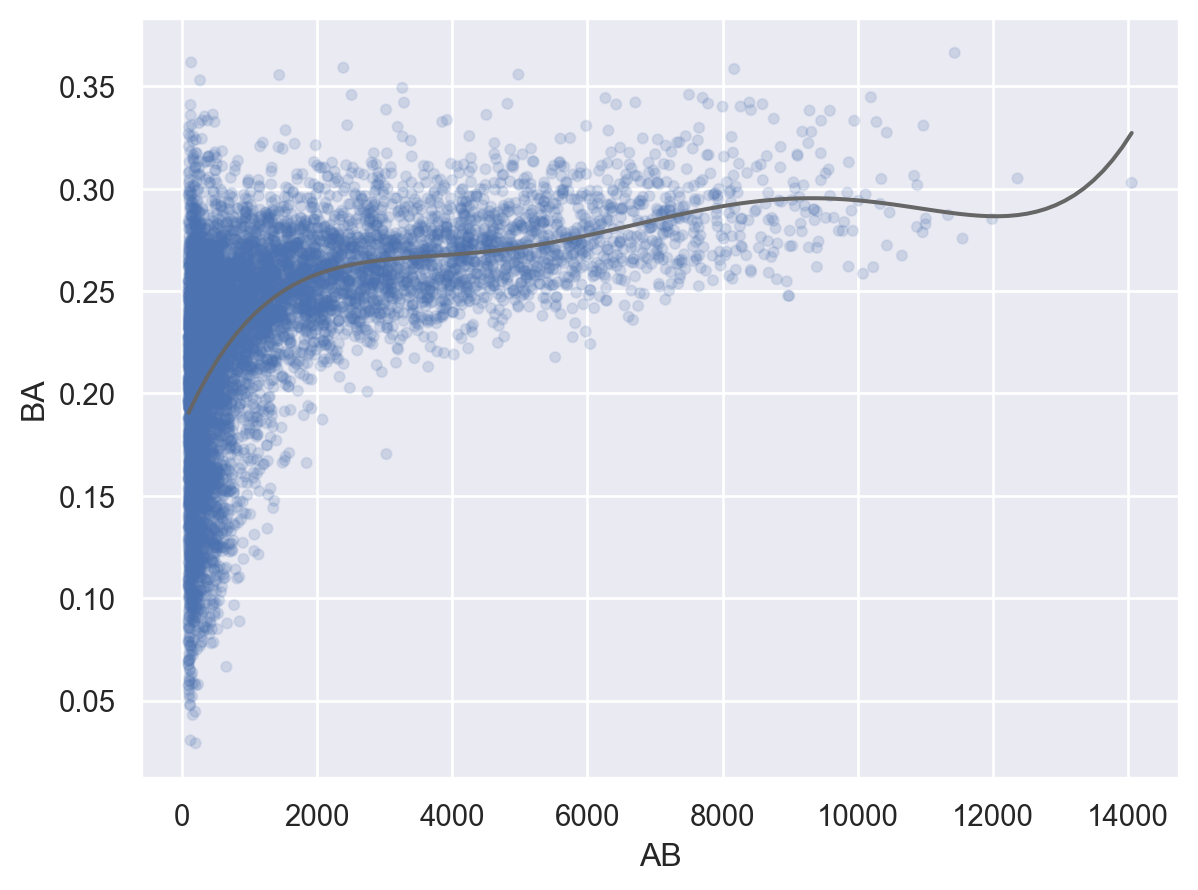
# AB: At Bats 타석에 나선 횟수, H: Hits; times reached base 출루한 횟수batters = batting.groupby("playerID")[["H", "AB"]].sum()batters = batters.assign( BA =lambda x: x.H / x.AB # BA: batting average 타율)batters
H AB BA
playerID
aardsda01 0.00000 3.00000 0.00000
aaronha01 3771.00000 12364.00000 0.30500
aaronto01 216.00000 944.00000 0.22881
... ... ... ...
zuvelpa01 109.00000 491.00000 0.22200
zuverge01 21.00000 142.00000 0.14789
zwilldu01 364.00000 1280.00000 0.28437
[17661 rows x 3 columns]
# filtering없이 보았을 때와 비교해서 어느 정도 제외할지 고민( so.Plot(batters.query('AB > 100'), x="AB", y="BA") .add(so.Dots(alpha=.1)) .add(so.Line(color=".4"), so.PolyFit(5)))
# 1번 기회를 얻은 타자... 타율 100%batters.sort_values("BA", ascending=False).head(10)
H AB BA
playerID
paciojo01 3.00 3.00 1.00
gallaja01 1.00 1.00 1.00
sellsda01 1.00 1.00 1.00
... ... ... ...
kehnch01 2.00 2.00 1.00
devinha01 2.00 2.00 1.00
liddeda01 1.00 1.00 1.00
[10 rows x 3 columns]